
Von evcc erfasste Daten langfristig speichern und aufbereiten
 geschrieben von Stefan, zuletzt aktualisiert am
geschrieben von Stefan, zuletzt aktualisiert am


evcc ist eine Software die sich um das Aufladen von Elektroautos mit möglichst viel selbst erzeugtem Strom kümmert. Dabei wird der aktuelle Überschuss ermittelt und basierend darauf die Ladung gestartet. Die Höhe der möglichen Ladeleistung wird stufenlos von evcc in Echtzeit überwacht und an den Überschuss angepasst. Eine ausführliche Anleitung zu evcc findet ihr auch bei uns.
evcc zeigt in seiner schlichten Benutzeroberfläche aber nur die aktuellen Messwerte an. Langfristige Auswertungen sind aktuell in evcc noch nicht möglich. Wir zeigen euch in dieser Anleitung, wie ihr evcc einstellen könnt, um alle wichtigen Messdaten in einer Datenbank abzuspeichern. Diese könnt ihr dann jederzeit nach beliebigen Kriterien abrufen und auswerten. Bei dieser Anleitung gehe ich davon aus, dass evcc auf einem Raspberry Pi läuft, so wie von uns in der evcc Anleitung empfohlen.
Achtung: ihr benötigt für die InfluxDB2 zwingend eine 64bit OS-Version. Dies ist erst ab dem Raspberry Pi 3 (inkl 4) möglich. Ältere Raspberry Pi (1/2) mit 32 bit Betriebssystem werden leider nicht unterstützt.
Die Datenbank
Die bekanntesten Datenbanksysteme sind sicherlich MySQL oder die MicrosoftSQL. Für das Abspeichern von zeitbasierten Datensätzen eignet sich aber die InfluxDB besser, da diese genau auf diesen Zweck ausgelegt ist und sowohl die Speichergröße als auch die Abfragegeschwindigkeit bei zeitbasierten Datensätzen besser ist als bei den etablierten Datenbanken.
Konkret verwenden wir die InfluxDB 2, welche deutliche Verbesserungen zu älteren Versionen aufweist und durch die neue Webverwaltung bereits sehr viele Möglichkeiten besitzt. Die Datenbank wird von evcc nativ unterstützt, so dass nicht viel manuelle Konfiguration erforderlich ist.
Zunächst verbinden wir uns via SSH mit dem Raspberry Pi, ihr könnt aber auch lokal am Raspberry Pi das Terminal benutzen. Als erstes binden wir mit den folgenden zwei Befehlen das InfluxDB Repository ein:
sudo curl https://repos.influxdata.com/influxdata-archive.key | gpg --dearmor | sudo tee /usr/share/keyrings/influxdb-archive-keyring.gpg >/dev/null
sudo echo "deb [signed-by=/usr/share/keyrings/influxdb-archive-keyring.gpg] https://repos.influxdata.com/debian $(lsb_release -cs) stable main" | sudo tee /etc/apt/sources.list.d/influxdb.list
Nun aktualisieren wir den Paketmanager apt, welcher nun auch die InfluxDB Quellen umfasst:
sudo apt-get update
Anschließend installieren wir nun die InfluxDB:
sudo apt-get install influxdb2
Damit ist die Datenbank auch bereits installiert und als Systemdienst eingerichtet. D.h. die Datenbank startet sich automatisch auch nach einem Neustart des Systems. Die Weboberfläche der InfluxDB ist nun über den Browser mit der IP-Adresse http://localhost:8086 erreichbar, wobei ihr "localhost" durch die IP-Adresse eures Raspberry Pis ersetzen müsst.
Benutzer erstellen
InfluxDB Access Token
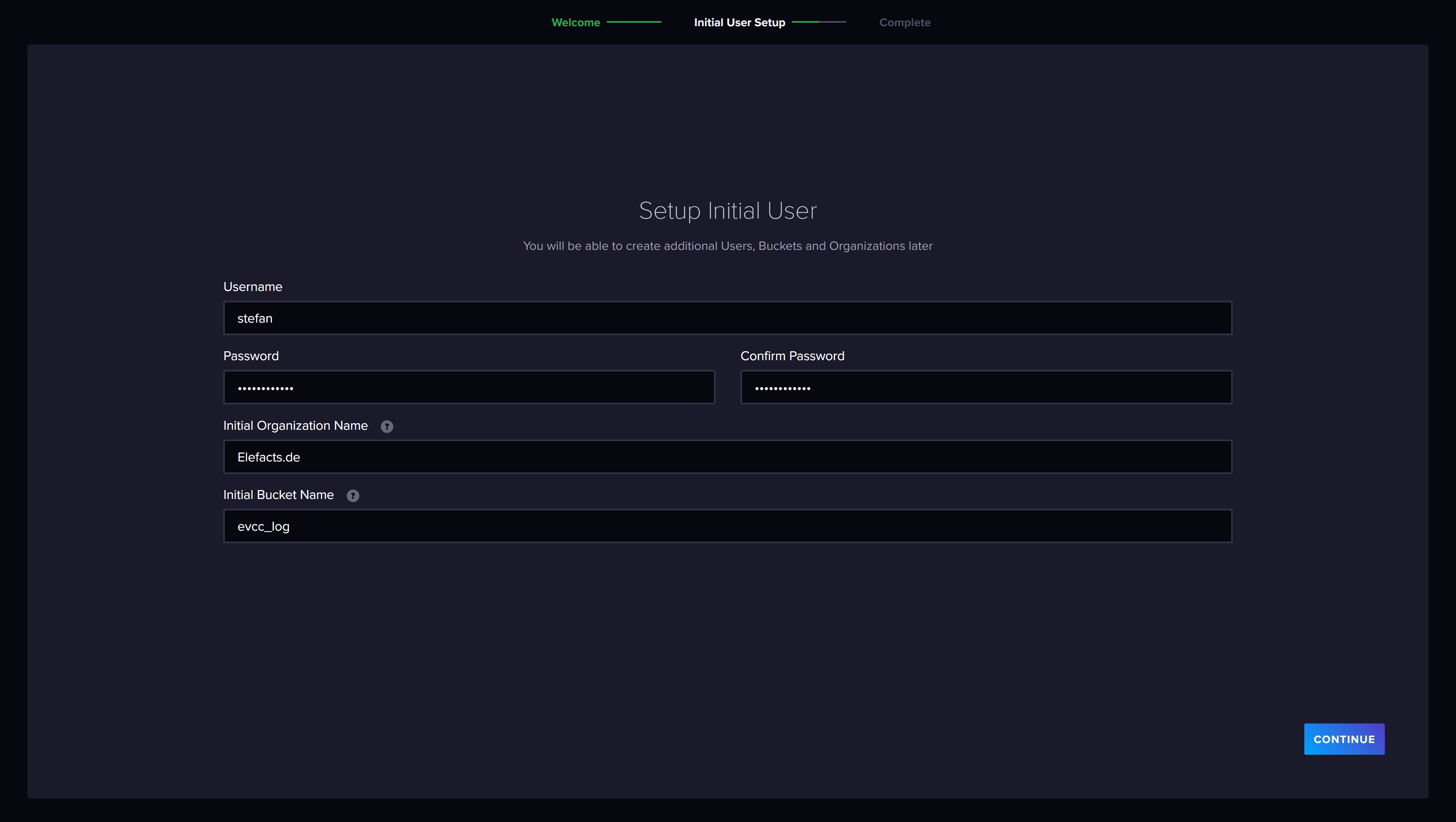
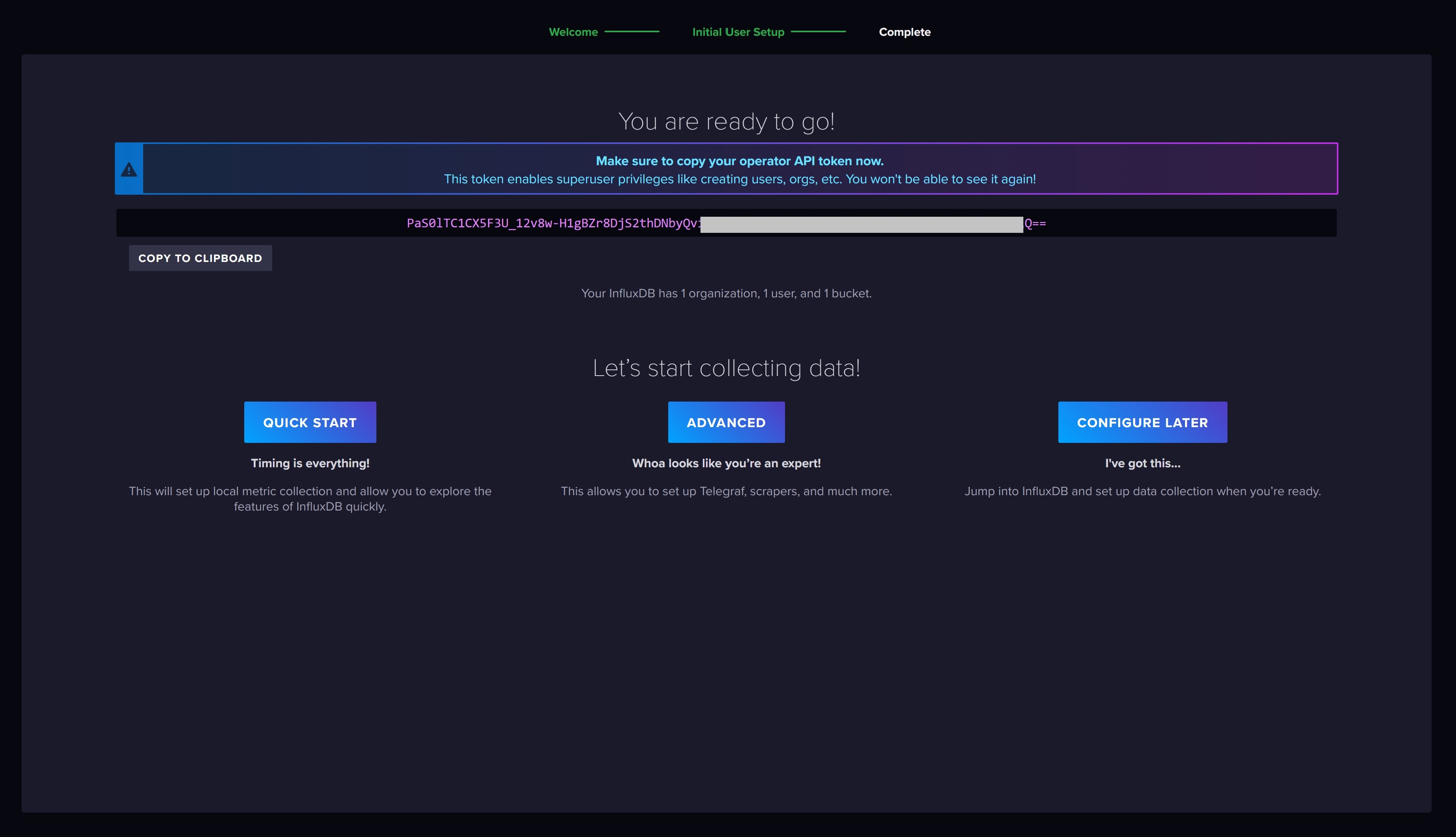
Über die Weboberfläche erstellen wir uns zunächst ein Benutzerkonto. Wichtig ist hier das Access Token, welches für euren Benutzer generiert wird. Dieses müsst ihr euch notieren, denn wir benötigen das Token um uns aus anderen Quellen mit der Datenbank zu verbinden. Bei der Erstellung legt ihr auch die Tabelle in der Datenbank fest, in der die evcc Daten gespeichert werden sollen. In InfluxDB nennt sich die Tabelle "Bucket". Ich habe hier evcc_log gewählt.
In der evcc.yaml Konfigurationsdatei von evcc, die im Verzeichnis /etc des Raspberry Pi liegt müssen wir nun die Speicherung der Daten in die InfluxDB festlegen. Dazu fügen wir folgenden Abschnitt in die Datei ein. Ihr müsst die Daten noch an eure anpassen, welche ihr während der Benutzererstellung in der InfluxDB Weboberfläche eingegeben habt.
influx: url: http://localhost:8086 database: evcc_log token: PaS0lTC1CX5F3xxxx4PfpvMiQ== org: Elefacts.de
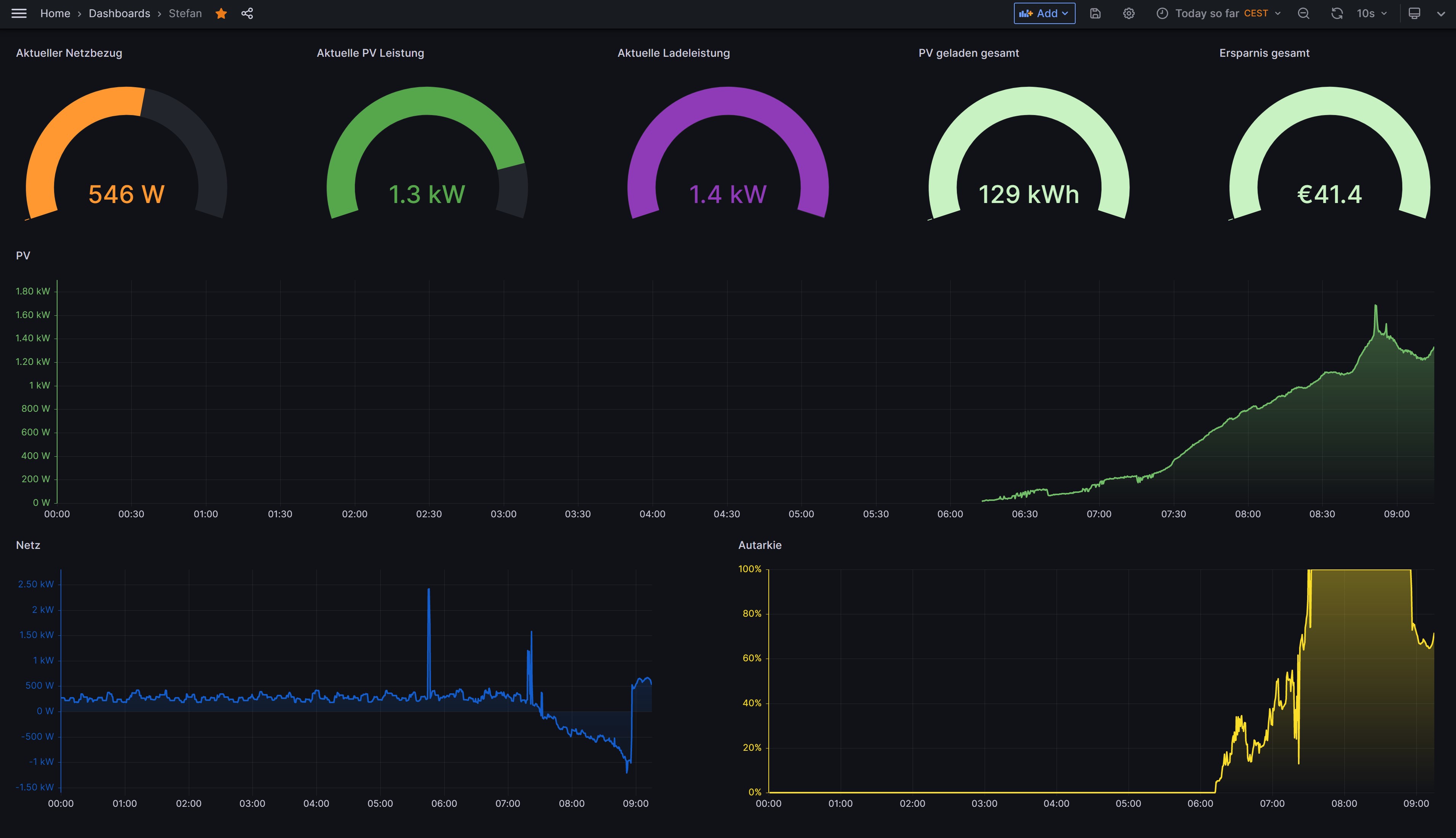
Nach einem Neustart von evcc landen nun alle ermittelten Messdaten automatisch in der InfluxDB. In der Weboberfläche der InfluxDB könnt ihr direkt prüfen, ob Daten aus evcc in eurer Bucket abgelegt werden. Dazu navigiert ihr über das seitliche Menü auf das Icon mit dem nach Oben gerichteten Pfeil der für Load Data steht. Hier wählt ihr über Buckets eure evcc Bucket aus, in meinem Fall evcc_log.
Ihr seht nun den Data Explorer. Wählt hier euer Bucket aus. Im Unterordner "_measurement" findet ihr alle von evcc erfassten Messwerte. Das sind recht viele. Als Beispiel habe ich hier einmal Gridpower ausgewählt. Anschließend klickt ihr auf value um die erfassten Messwerte von diesem Wert zu sehen. Die Abfrage schickt ihr über die rechte Submit Schaltfläche ab. Ihr solltet nun eine Statistik der von evcc abgelegten Messwerte für Gridpower angezeigt bekommen.
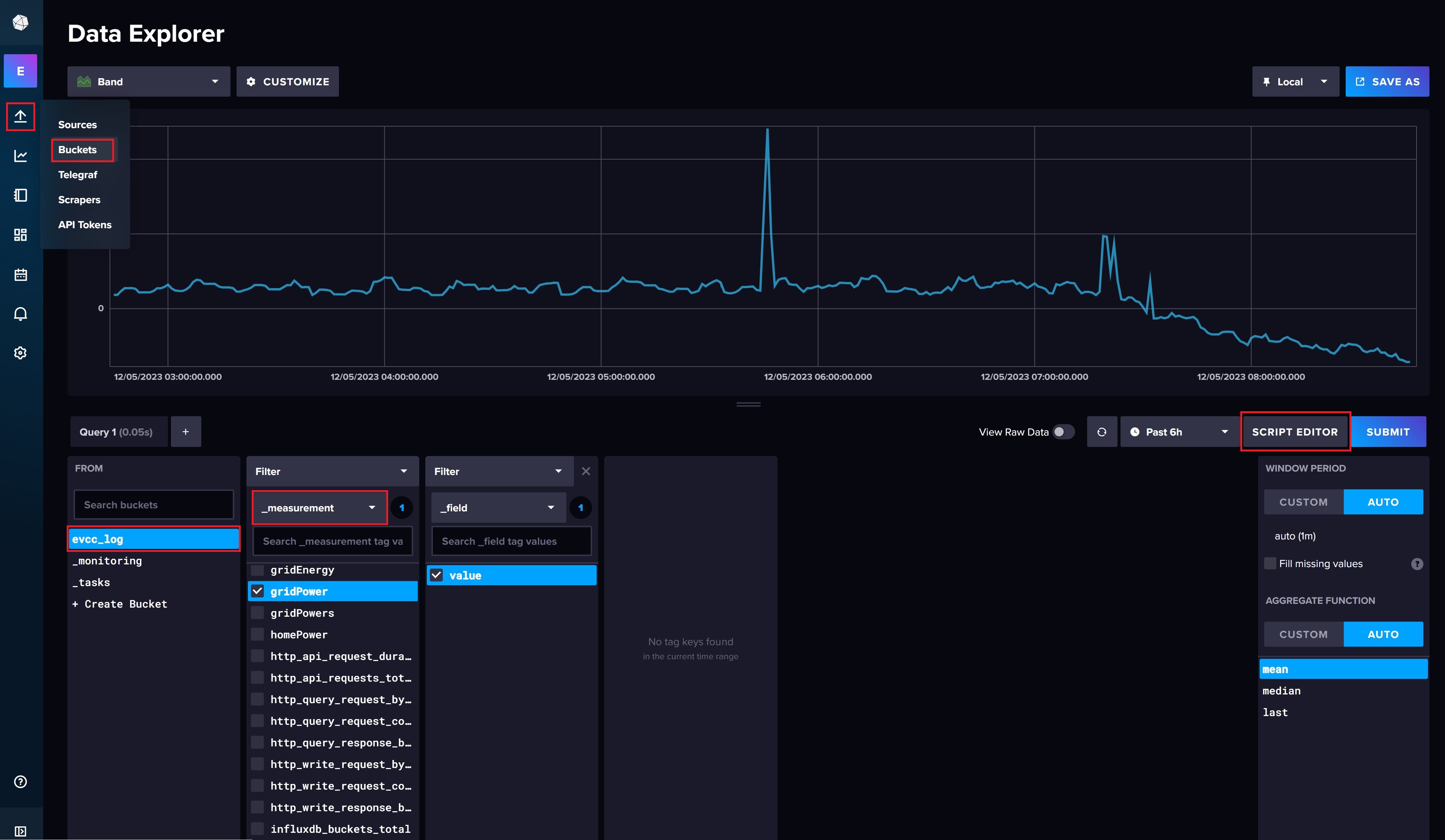
Neben der Submit Schaltfläche könnt ihr zwischen dem eben genutzem Query Builder und dem Script Editor, in dem ihr manuell die Abfrage schreiben könnt, umschalten. Das ist sinnvoll, weil wir uns hier die von uns erstellte Abfrage rauskopieren und in unsere Abfrageoberfläche überführen können.
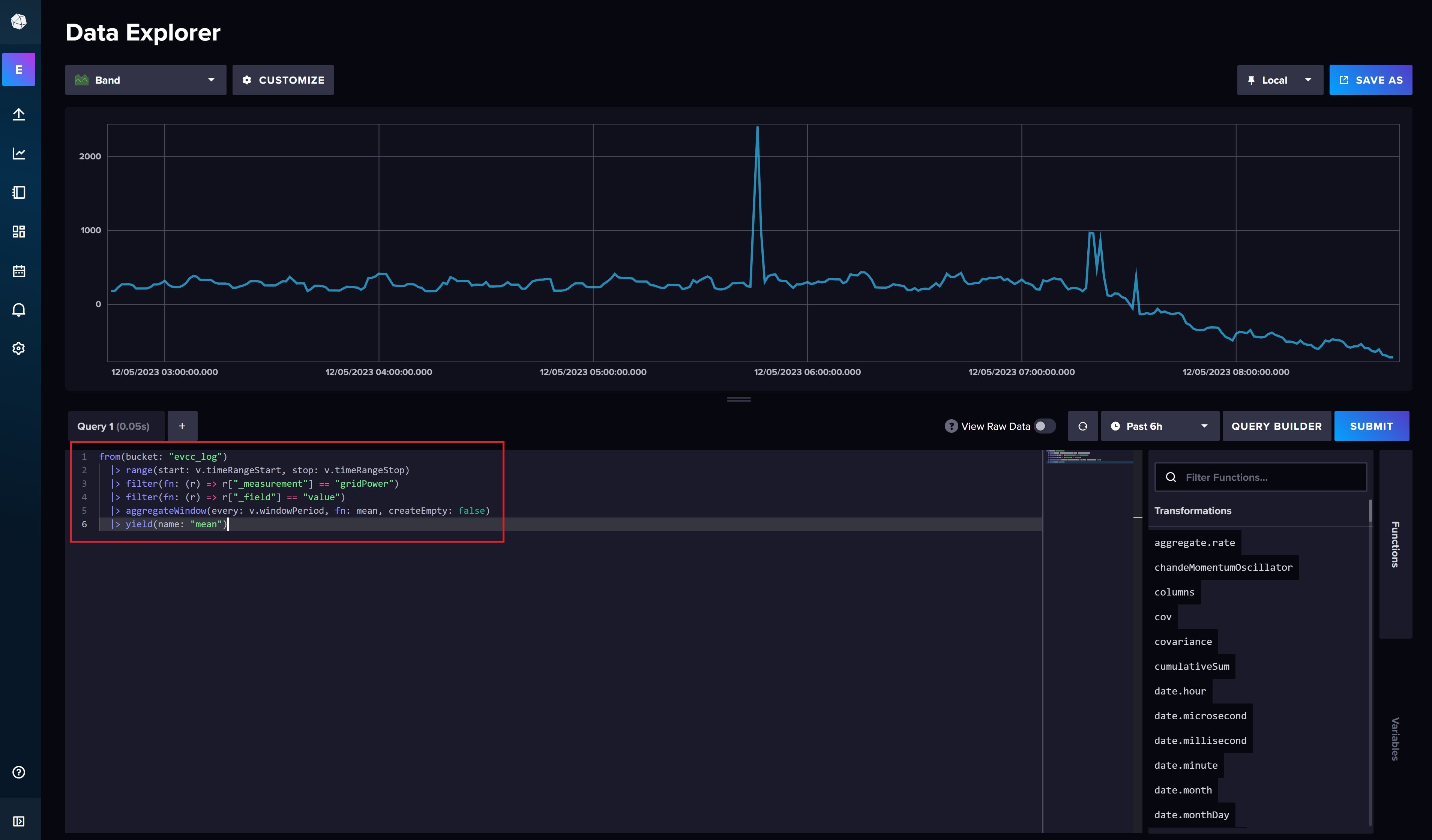
Die InfluxDB Query für unser Beispiel der Gridpower würde folgendermaßen aussehen:
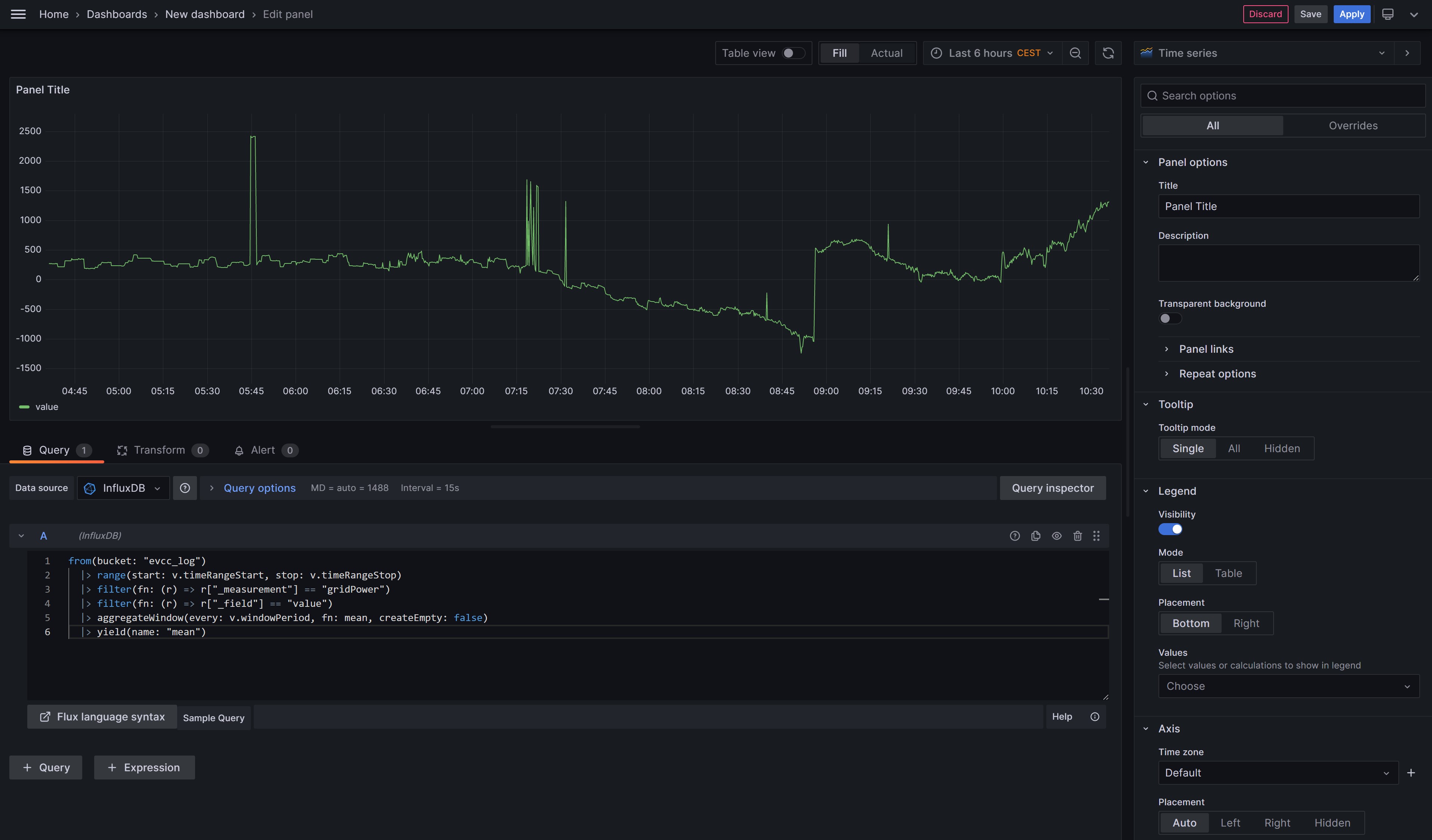
from(bucket: "evcc_log") |> range(start: v.timeRangeStart, stop: v.timeRangeStop) |> filter(fn: (r) => r["_measurement"] == "gridPower") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: v.windowPeriod, fn: mean, createEmpty: false) |> yield(name: "mean")
Wie ihr seht, lassen sich bereits in der InfluxDB Weboberfläche die evcc Messwerte komfortabel anzeigen. Unsere Gridpower Abfrage können wir über die Save As Schaltfläche oben rechts auch abspeichern und in ein Dashboard überführen.
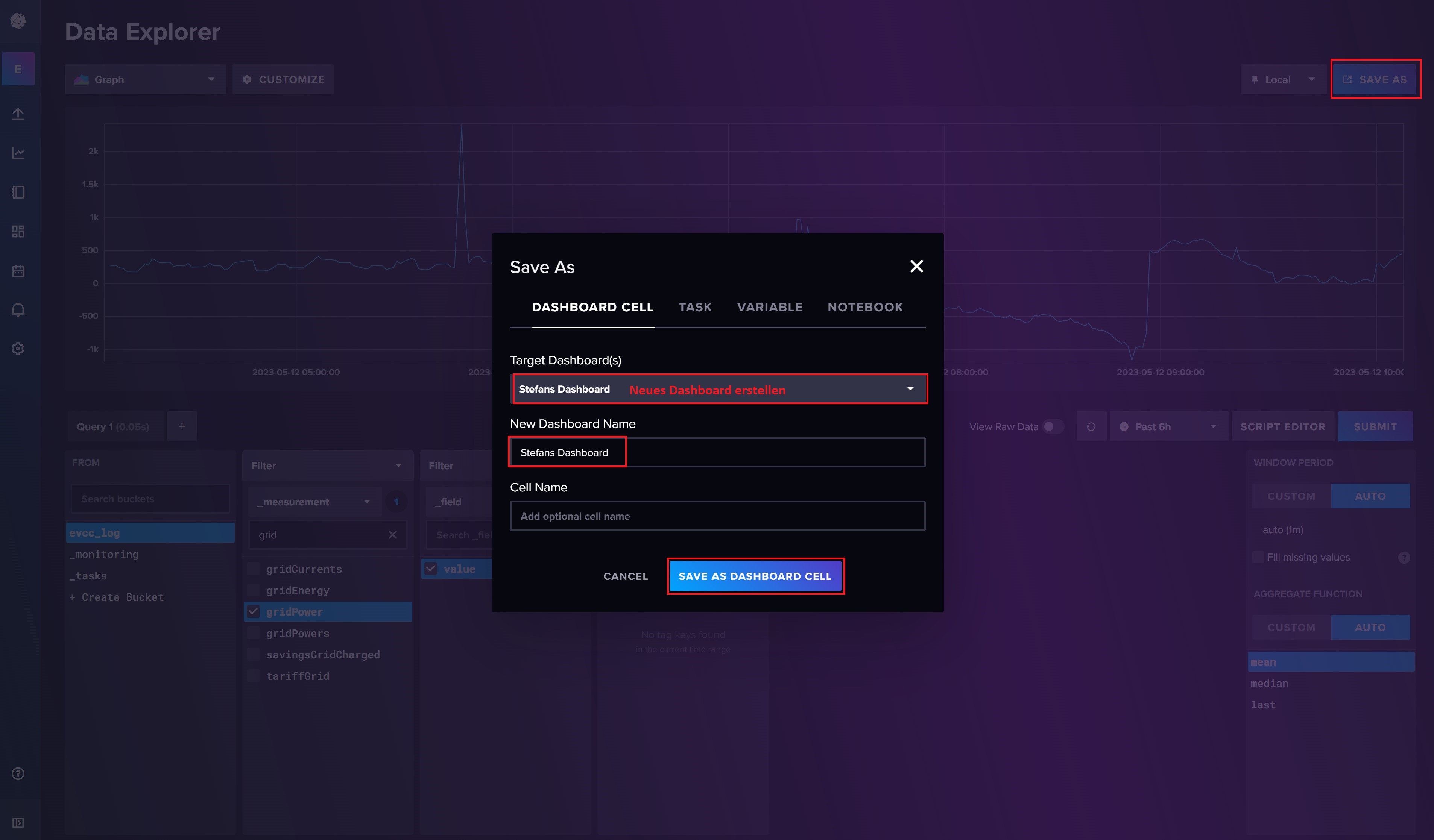
Ihr solltet nun euer Dashboard sehen, auf dem ihr die GridPower aus evcc sehen könnt. Im Dashboard lässt sich komfortabel ein Zeitraum auswählen, zum Beispiel die Anzeige der Daten der letzten 24 Stunden.
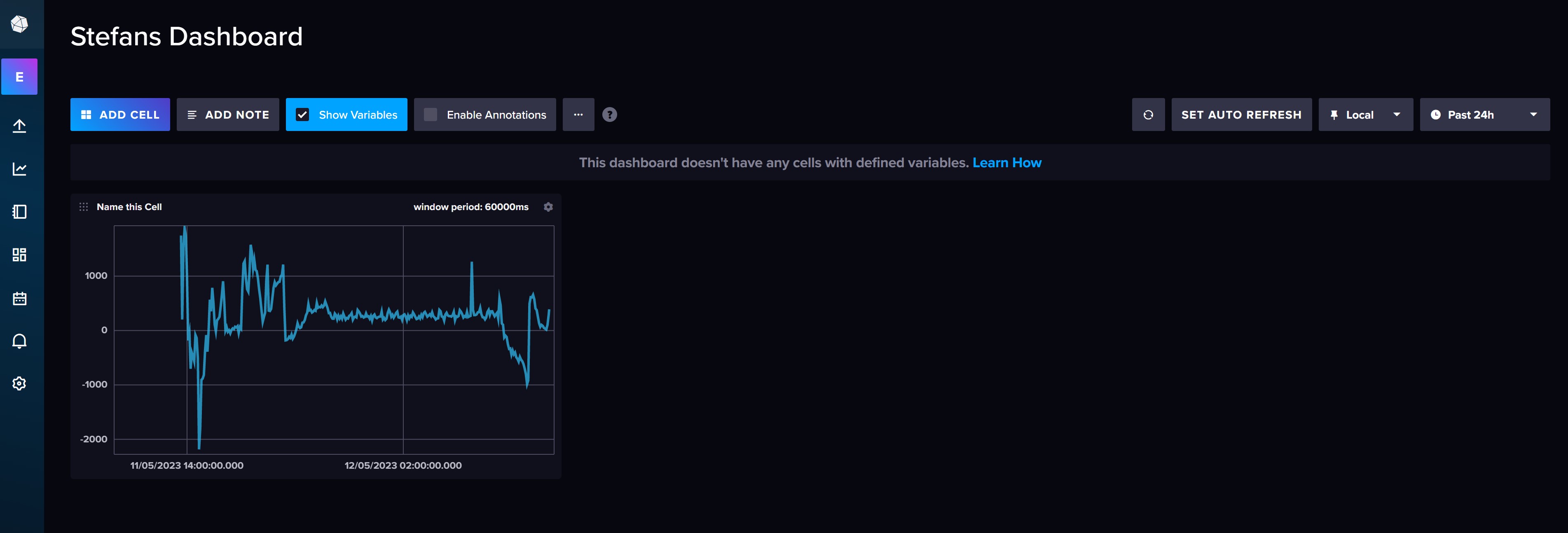
Alle, die diese einfache Dashboard Ansicht der InfluxDB Weboberfläche bereits als ausreichend empfinden, könnten nun damit beginnen alle gewünschten Messwerte dem Dashboard wie beschrieben hinzuzufügen.
Mehr Möglichkeiten mit Grafana
Ich selbst nutze das InfluxDB eigene Dashboard allerdings nicht, da es für mich nicht alle Möglichkeiten bietet die ich gerne hätte. Die InfluxDB Weboberfläche nutze ich zwar regelmäßig, allerdings nur um mir Abfragen über den Query Builder zusammen zu bauen.
Für die Visualisierung setze ich auf eine weitere Software: Grafana. Grafana kann sich mit sehr vielen Datenquellen (allen voran natürlich MySQL oder MicrosoftSQL) verbinden und unterstützt auch nativ die vons uns genutzte InfluxDB. Die Installation von Grafana auf dem Raspberry Pi wird in der hauseigenen Dokumentation beschrieben und ähnelt im Vorgehen der Installation der InfluxDB.
Zunächst müssen alle Abhängigkeiten installiert werden, falls nicht bereits vorhanden:
sudo apt-get install -y apt-transport-https software-properties-common wget
Anschließend wird wieder das Repository der Software in unseren Paketmanager apt integriert:
sudo mkdir -p /etc/apt/keyrings/
wget -q -O - https://apt.grafana.com/gpg.key | gpg --dearmor | sudo tee /etc/apt/keyrings/grafana.gpg > /dev/null
echo "deb [signed-by=/etc/apt/keyrings/grafana.gpg] https://apt.grafana.com stable main" | sudo tee -a /etc/apt/sources.list.d/grafana.list
Aktualisierung des lokalen Repositorys:
sudo apt-get update
... und Installation von Grafana:
sudo apt-get install -y grafana
Da sich Grafana im Gegensatz zur InfluxDB nicht selbst als Systemdienst registriert, müssen wir dies manuell erledigen:
sudo /bin/systemctl enable grafana-server
Gestartet wird Grafana dann über:
sudo /bin/systemctl start grafana-server
Die Weboberfläche von Grafana ist über http://localhost:3000 erreichbar, "localhost" muss wieder durch die IP-Adresse eures Raspberry Pis ersetzt werden. Hinweis: der erste Start des Grafana Servers kann bis zu 5 Minuten dauern. Die Weboberfläche ist anfangs ggf. nicht zu erreichen. Einfach etwas warten, dann sollte es gehen.
Für die erste Anmeldung nutzt ihr den Benutzer admin mit dem Passwort admin. Anschließend werdet ihr aufgefordert ein neues Passwort für den admin Benutzer festzulegen.
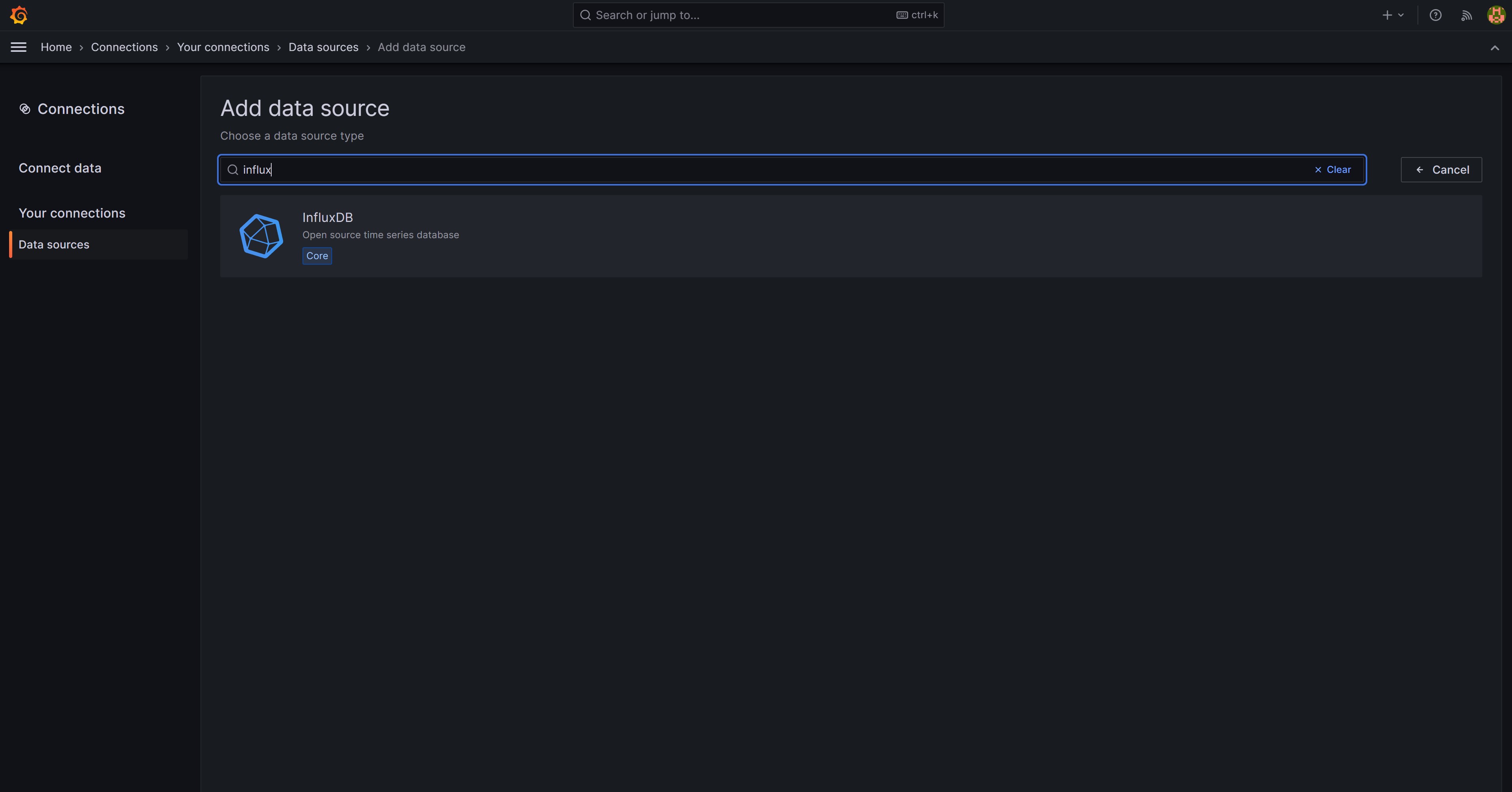
Damit wir aus Grafana auf unsere Daten, die in der InfluxDB liegen, zugreifen können, müssen wir zunächst eine Verbindung zur InfluxDB anlegen. Diese können wir über das seitliche Menü und dann Connections und Your connections anlegen. Im Suchfeld könnt ihr bequem nach der Schnittstelle zur InfluxDB suchen.
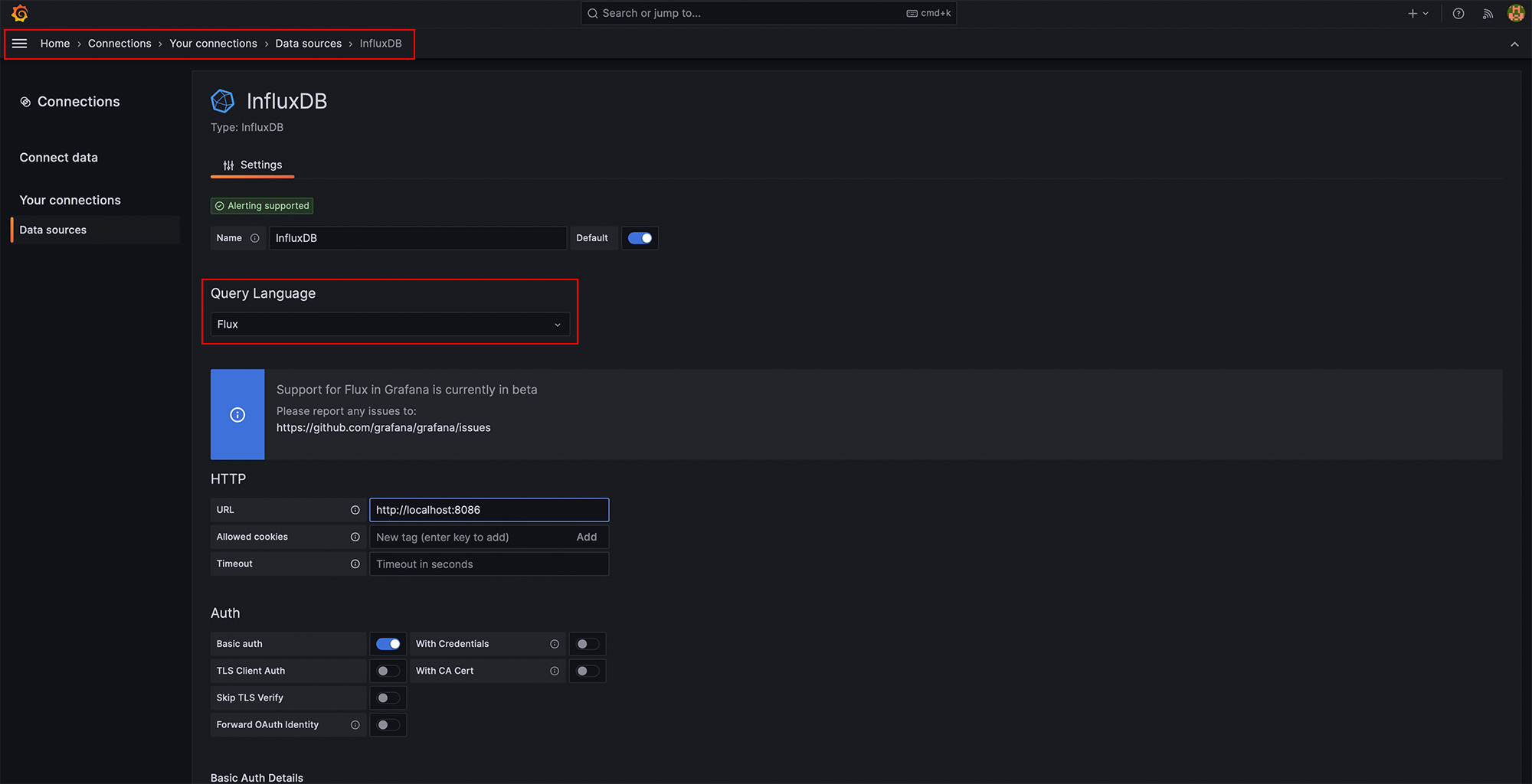
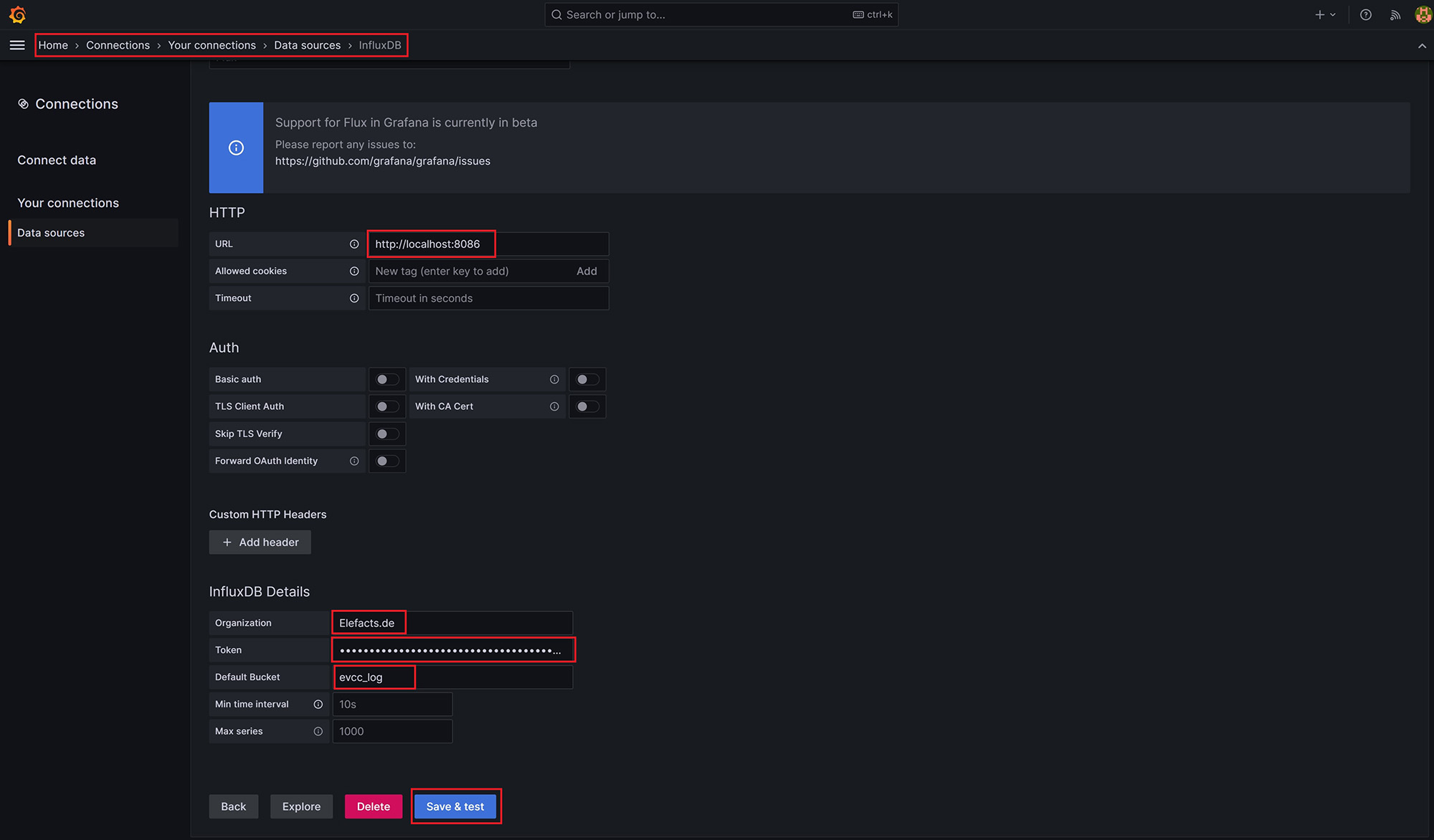
Hier ändern wir als erstes die Query Language auf Flux und dann geben wir die Verbindungsdaten des InfluxDB-Servers ein. Hier benötigt ihr zudem wieder euer InfluxDB Token.
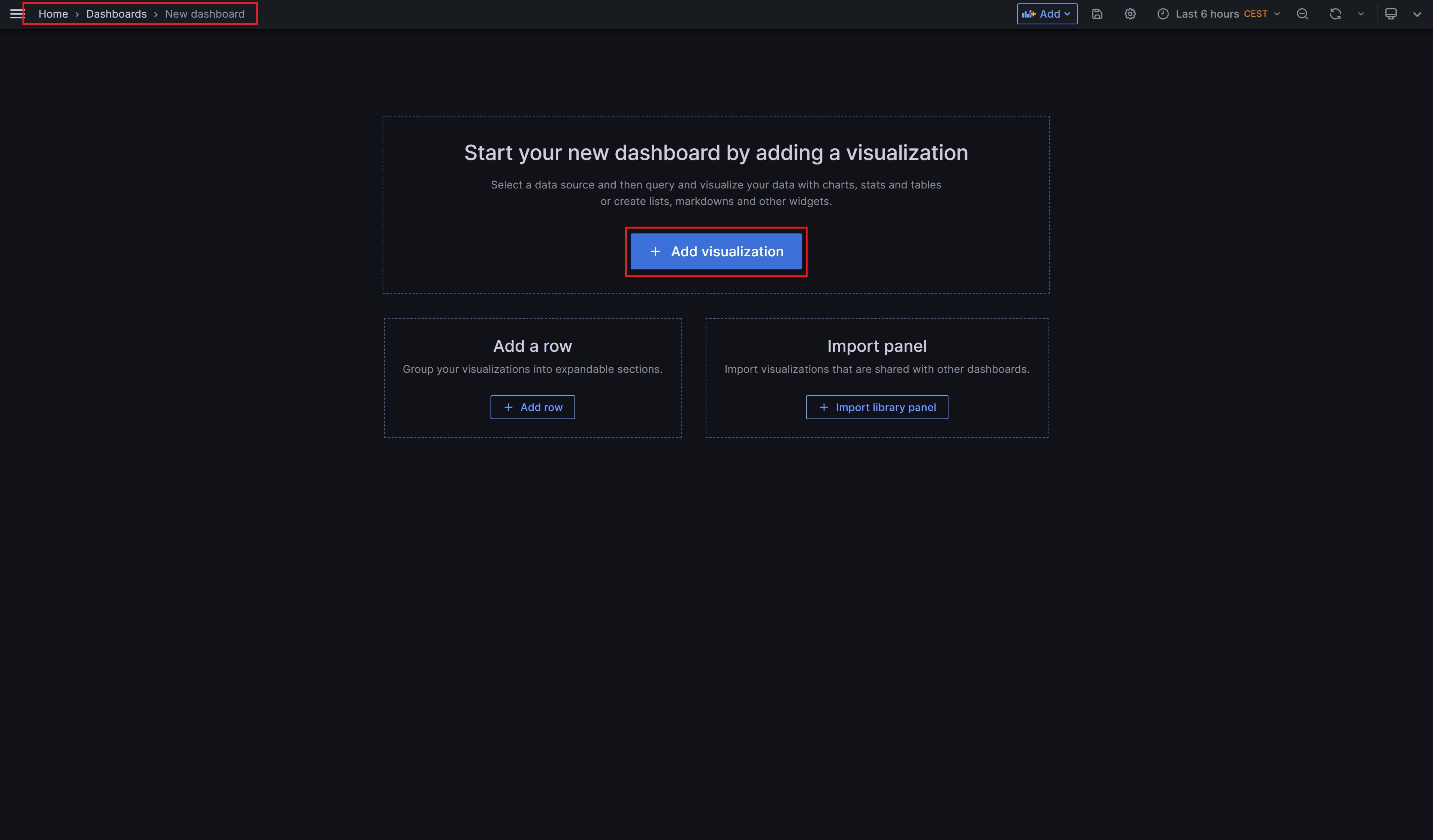
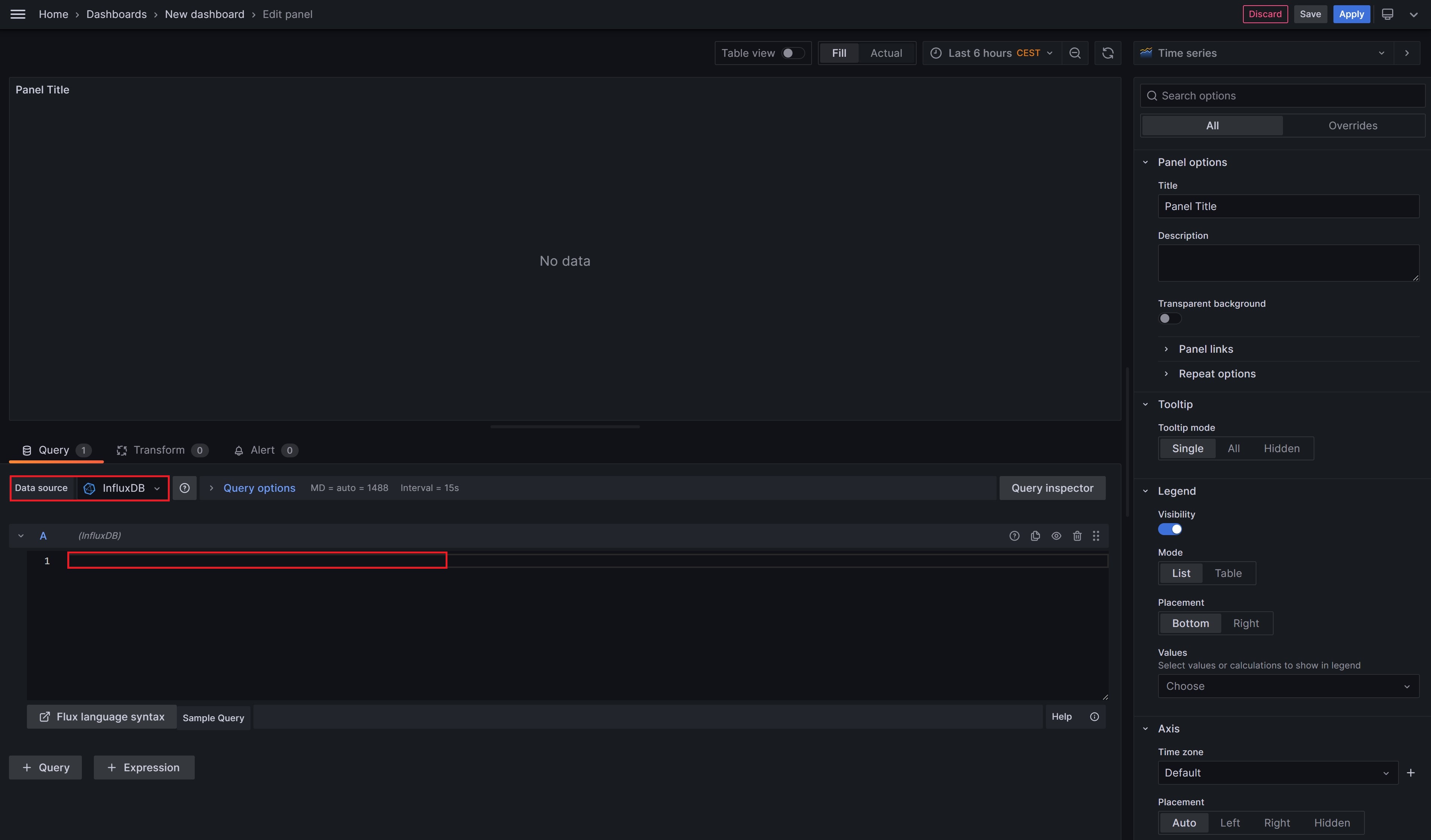
Ist die Verbindung zur InfluxDB eingerichtet, können wir uns nun ein neues Dashboard erstellen und einen ersten Chart hinzufügen. Dazu klicken wir auf Add visualization und wählen als Datenquelle unsere InfluxDB aus. Ich verwende hier exemplarisch die identische Query, die wir auch in der InfluxDB genutzt haben und die weiter oben in diesem Artikel steht. Diese könnt ihr kopieren und dann in Grafana einfügen.
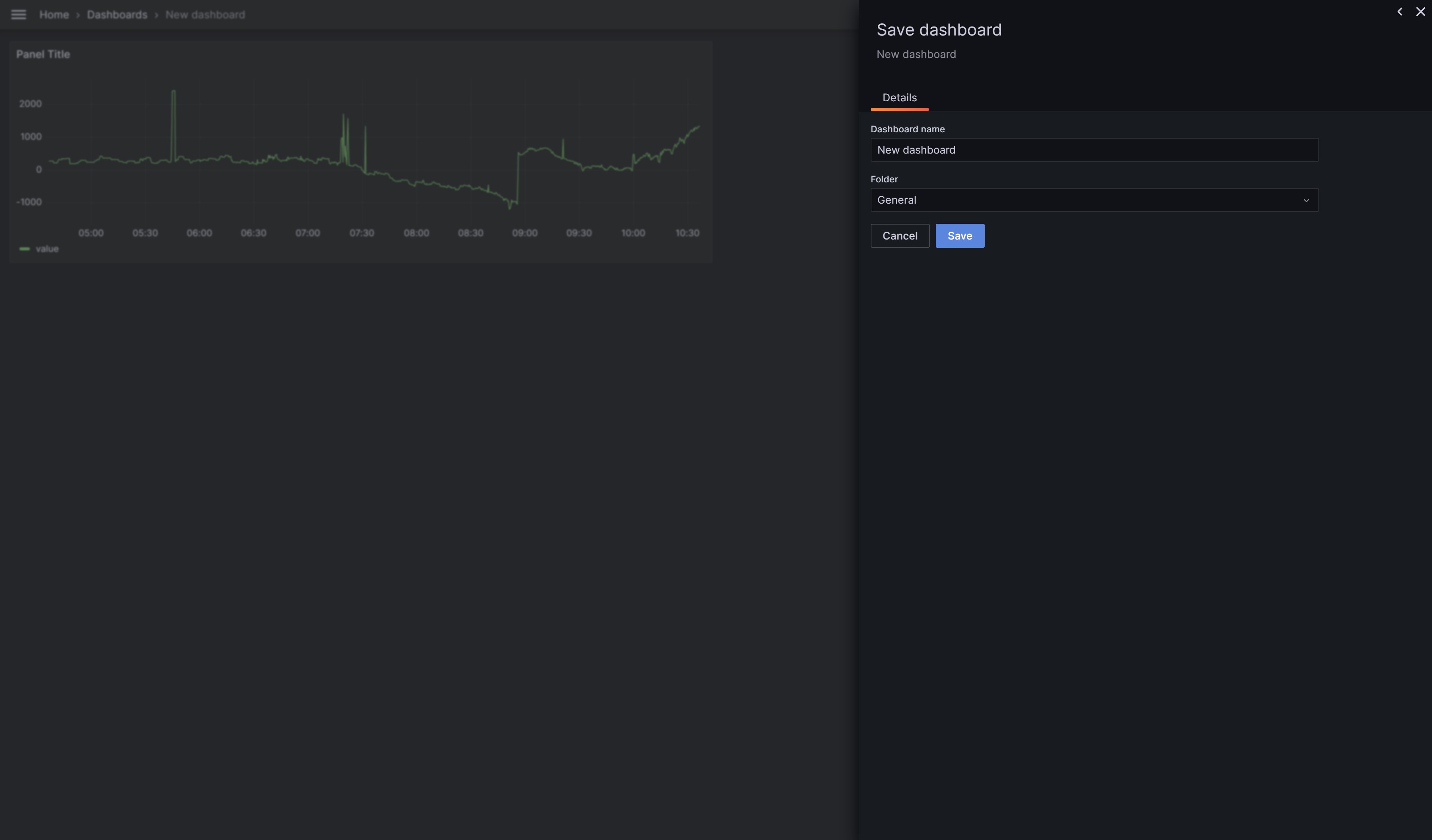
Ihr könnt nun den Chart optisch an eure Bedürfnisse anpassen und mit Apply speichern. Ihr gelangt dann wieder zu eurem Dashboard. Ganz wichtig: ihr müsst euer Dashboard zusätzlich selbst auch abspeichern, ansonsten gehen alle Änderungen verloren.
Wie bei evcc könnt ihr auch euer Grafana Dashboard auf Wunsch auch auf eurem Mobilgerät anzeigen, die Oberfläche ist responsiv aufgebaut. Grafana selbst könnt ihr natürlich nicht nur für evcc nutzen, sondern für sehr viele andere Datenquellen auch. Es lassen sich auch mehrere Dashboards erstellen, so dass ihr die Ansichten auf Wunsch nach Thematik trennen könnt.
Beispielabfragen
Hier habe ich euch eine kleine Auswahl an Abfragen (InfluxDB Queries) zusammengestellt, die ich aktuell benutze.
PV-Leistung (Historie)
from(bucket: "evcc_log") |> range(start: v.timeRangeStart, stop: v.timeRangeStop) |> filter(fn: (r) => r["_measurement"] == "pvPower") |> filter(fn: (r) => r["_field"] == "value") |> filter(fn: (r) => r["id"] != "1" and r["id"] != "2") |> filter(fn: (r) => r["_value"] > 0) |> aggregateWindow(every: v.windowPeriod, fn: mean, createEmpty: false) |> yield(name: "mean")
PV-Leistung (Aktuell)
from(bucket: "evcc_log") |> range(start: v.timeRangeStart, stop: v.timeRangeStop) |> filter(fn: (r) => r["_measurement"] == "pvPower") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: v.windowPeriod, fn: last, createEmpty: false) |> yield(name: "last")
Autarkie
from(bucket: "evcc_log") |> range(start: v.timeRangeStart, stop: v.timeRangeStop) |> filter(fn: (r) => r["_measurement"] == "greenShare") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: v.windowPeriod, fn: mean, createEmpty: false) |> yield(name: "mean")
Netzbezug (Aktuell)
from(bucket: "evcc_log") |> range(start: v.timeRangeStart, stop: v.timeRangeStop) |> filter(fn: (r) => r["_measurement"] == "gridPower") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: v.windowPeriod, fn: last, createEmpty: false) |> yield(name: "last")
Netzbezug (Historie)
from(bucket: "evcc_log") |> range(start: v.timeRangeStart, stop: v.timeRangeStop) |> filter(fn: (r) => r["_measurement"] == "gridPower") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: v.windowPeriod, fn: mean, createEmpty: false) |> yield(name: "mean")
Bei Links, die mit einem * gekennzeichnet sind, handelt es sich um Affiliate-Links, bei denen wir bei einem Kauf eine Vergütung durch den Anbieter erhalten.
Kommentare (20)

Jankil
 25.07.2025
25.07.2025
Hi Stefan, Danke für die Anleitung.
Könntest Du ein Screenshot teilen, wie dein aktuelles Dashboard aussieht? Wäre cool, hier mal ein paar Anregungen zu haben.
Könntest Du ein Screenshot teilen, wie dein aktuelles Dashboard aussieht? Wäre cool, hier mal ein paar Anregungen zu haben.

Stefan (Team)
17.04.2025
@Kami ich habe mittlerweile ein ganz anderes Dashboard mit vielen Integrationen, daher ist das leider nicht möglich bzw. auch nicht hilfreich.
Kami
04.04.2025
Tolle Anleitung
Dein Dashboard gefällt mir schon so. Kannst du es nicht komplett zur Verfügung stellen als Json?
Dein Dashboard gefällt mir schon so. Kannst du es nicht komplett zur Verfügung stellen als Json?
Karsten
17.11.2024
Letzter Kommentar :-) - vielleicht.
Um nur einen Wert bei pv-Aktuell zu erhalten musste ich die folgende Zeile hinzufügen:
|> filter(fn: (r) => r"id" == "1")
Es sah bei mir ein wenig seltsam bei den Werten aus, die in der influxdb gelandet sind. Ich weiß allerdings noch nicht, ob das die Lösung ist, die Sonne scheint gerade nicht.
Grüße
Um nur einen Wert bei pv-Aktuell zu erhalten musste ich die folgende Zeile hinzufügen:
|> filter(fn: (r) => r"id" == "1")
Es sah bei mir ein wenig seltsam bei den Werten aus, die in der influxdb gelandet sind. Ich weiß allerdings noch nicht, ob das die Lösung ist, die Sonne scheint gerade nicht.
Grüße
Karsten
17.11.2024
Oh - hat sich erledigt - unter Visualizations lassen sich viele verschiedene Möglichkeiten einstellen, manchmal sieht man den Wald vor Bäumen nicht - sorry:-)
Allerdings erhalte ich bei aktuell PV zwei Werte: value und value1 - wahrscheinlich das gleiche Problem, das oben schon mal beschrieben wurde.
Allerdings erhalte ich bei aktuell PV zwei Werte: value und value1 - wahrscheinlich das gleiche Problem, das oben schon mal beschrieben wurde.
Karsten
17.11.2024
Zunächst - vielen Dank, schon lang her, dass ich etwas mit Grafana gemacht hatte.
Zur Info - vielleicht interessant für andere: Mein pi hatte noch arm7 also 32 bit. Ich habe über die boot-config die 64 bit variante eingestellt und dann das binary von influxdbV2 manuell installiert (geladen und systemdienst gebaut) - das läuft, ein komplett-update war mir jetzt zu aufwändig.
Dann die Frage - ich bekomme die Historie angezeigt, aber die Einzelwerte funktionieren nicht, ich würde gern so etwas wie die "Tachometer" ganz oben sehen. Bei den Einzelwerten bekomme ich auch die Linien-Diagramme angezeigt.
Hat dazu noch jemand etwas heraus gefunden?
Viele Grüße
Zur Info - vielleicht interessant für andere: Mein pi hatte noch arm7 also 32 bit. Ich habe über die boot-config die 64 bit variante eingestellt und dann das binary von influxdbV2 manuell installiert (geladen und systemdienst gebaut) - das läuft, ein komplett-update war mir jetzt zu aufwändig.
Dann die Frage - ich bekomme die Historie angezeigt, aber die Einzelwerte funktionieren nicht, ich würde gern so etwas wie die "Tachometer" ganz oben sehen. Bei den Einzelwerten bekomme ich auch die Linien-Diagramme angezeigt.
Hat dazu noch jemand etwas heraus gefunden?
Viele Grüße
Stefan (Team)
11.09.2024
@Stephan: hab ich aktualisiert !
Stephan
11.09.2024
Leider ist die Installanleitung zu Grafana schon überholt. Es kommt gleich nach der ersten Befehlseingabe:n"Warning: apt-key is deprecated. Manage keyring files in trusted.gpg.d instead (see apt-key(8))."nnWas ist zu tun?
Stefan (Team)
05.02.2024
@Chris: wie bereitest Du die Daten auf ? Ich rate dir zu Grafana. Hier kann man dann einfach mehrere Queries in Grafana selbst addieren und dann das Ergebnis ausgeben.
Chris
04.02.2024
Hi Stefan ,
Vielen Dank für den super Job hier .
Ich hänge bei den Queries für die Gesamtwerte , also Netz , PV und Ladeleistung gesamt sowie die Gesamtsumme.
Was muss man da genau abfragen ?
Danke dir
Vielen Dank für den super Job hier .
Ich hänge bei den Queries für die Gesamtwerte , also Netz , PV und Ladeleistung gesamt sowie die Gesamtsumme.
Was muss man da genau abfragen ?
Danke dir
Dennis (Team)
24.07.2023
Moin Martin,
aus Sicherheitsgründen werden hier in den Kommentaren manche Sonderzeichen entfernt, daher noch mal zur Sicherheit, dein Code sieht so aus:
Korrekt? Wenn ja dürfte da auch nur 1 Wert stehen.
LG
Dennis
aus Sicherheitsgründen werden hier in den Kommentaren manche Sonderzeichen entfernt, daher noch mal zur Sicherheit, dein Code sieht so aus:
from(bucket: "evcclog") |> range(start: v.timeRangeStart, stop: v.timeRangeStop) |> filter(fn: (r) => r["_measurement"] == "pvPower") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: v.windowPeriod, fn: last, createEmpty: false) |> yield(name: "last")
Korrekt? Wenn ja dürfte da auch nur 1 Wert stehen.
LG
Dennis
Martin
23.07.2023
Eine super Anleitung! Danke dafür.
Ich baue das gerade in Grafana etwas um und stolpere über etwas.
Bekommt ihr bei
from(bucket: "evcclog")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r"measurement" == "pvPower")
|> filter(fn: (r) => r"field" == "value")
|> aggregateWindow(every: v.windowPeriod, fn: last, createEmpty: false)
|> yield(name: "last")
auch 2 Values zurückgeliefert?
Ich hab mich noch nicht wirklich durch die Daten in der influx gewühlt; vielleicht übersehe ich auch einfach etwas. In Deiner 1. Übersicht ist es nur 1 Wert.
Grüße!
Ich baue das gerade in Grafana etwas um und stolpere über etwas.
Bekommt ihr bei
from(bucket: "evcclog")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r"measurement" == "pvPower")
|> filter(fn: (r) => r"field" == "value")
|> aggregateWindow(every: v.windowPeriod, fn: last, createEmpty: false)
|> yield(name: "last")
auch 2 Values zurückgeliefert?
Ich hab mich noch nicht wirklich durch die Daten in der influx gewühlt; vielleicht übersehe ich auch einfach etwas. In Deiner 1. Übersicht ist es nur 1 Wert.
Grüße!
Stefan (Team)
05.07.2023
Zum Thema Abfragen: für jeden Chart musst Du in der Regel eine Datenbankabfrage machen. Man kann auch mehrere Abfragen in einem Chart verbinden/kombinieren wenn man möchte. Das habe ich in meiner Beispielsansicht aber nicht gemacht.
Tobias Huber
04.07.2023
@Stefan: Bei deinen InfluxDB Queries unten im Artikel muss es aber from(bucket: "evcclog") lauten, also das log fehlt :-)
Was ich nicht verstehe: Muss ich für jede grafische Darstellung eine einzelne separate Querie machen oder ist das eine "große"? Wie hast du diese tolle grafische Darstellung siehe erstes Bild in diesem Artikel hinbekommen?
Was ich nicht verstehe: Muss ich für jede grafische Darstellung eine einzelne separate Querie machen oder ist das eine "große"? Wie hast du diese tolle grafische Darstellung siehe erstes Bild in diesem Artikel hinbekommen?
Stefan (Team)
03.07.2023
@Tobi: das hatte ich sowie schon vor, habs aber ehrlich gesagt dann vergessen. Ich habe jetzt ein paar Abfragen für die InfluxDB am Ende des Artikels eingefügt.
Die Sammlung der EVCC Daten mache ich nicht mehr so wie in dieser Anleitung beschrieben, weil sich bei mir zu viele Daten angesammelt haben und die Dateigröße der Datenbank schnell zu groß wurde. Ich empfehle hier meinen neuen Lösungsweg: MQTT-Daten mit Node-RED in InfluxDB2 speichern
Die Sammlung der EVCC Daten mache ich nicht mehr so wie in dieser Anleitung beschrieben, weil sich bei mir zu viele Daten angesammelt haben und die Dateigröße der Datenbank schnell zu groß wurde. Ich empfehle hier meinen neuen Lösungsweg: MQTT-Daten mit Node-RED in InfluxDB2 speichern
Tobi
02.07.2023
@Stefan, könntest du bitte deine komplette InfluxDB Query hier einstellen. Danke!
Ich bekomm das einfach nicht so toll dargestellt, wie du siehe erstes Bild in dieser Anleitung!
Ich bekomm das einfach nicht so toll dargestellt, wie du siehe erstes Bild in dieser Anleitung!
Stefan (Team)
25.05.2023
@CamelCase: Danke, habe ich nachträglich eingefügt
CamelCase
24.05.2023
Zunächst mal, das ist eine schöne Anleitung; Danke dafür.
In der Zeile für die Hinzufügung des InfluxDB-Repositories fehlt nur das "main" hinter "stable", damit "apt update" danach damit klar kommt.
In der Zeile für die Hinzufügung des InfluxDB-Repositories fehlt nur das "main" hinter "stable", damit "apt update" danach damit klar kommt.
Stefan (Team)
23.05.2023
Hi Gottfried, Du benötigst wie im Artikel beschrieben dringend ein 64bit Betriebssystem. Ich vermute Du hast ein 32bit Betriebssystem auf deinem Raspberry Pi installiert. Für 32 bit gibt es kein Paket für die InfluxDB2. Wenn Du die "2" einfach weglässt, installierst Du die InfluxDB 1.x, die ist in der Verwendung völlig anders als ich es hier für die InfluxDB2 beschrieben habe!
Ich empfehle dir ein 64bit Betriebssystem auf deinem Raspberry Pi 3B zu installieren, der ist 64 bit fähig !
Ich empfehle dir ein 64bit Betriebssystem auf deinem Raspberry Pi 3B zu installieren, der ist 64 bit fähig !
Gottfried
18.05.2023
Leider funktionierte die Installation von InfluxDB auf meinem Raspi 3B nicht mit den 4 Befehlen wie im Artikel beschrieben. Am Ende hieß es immer "Paket nicht gefunden". Nach Recherche auf https://repos.influxdata.com/debian/dists/bullseye/stable/ habe ich die 2 in der letzten Zeile weggelassen, also sudo apt-get install influxdb - und es ging!
Nun ist zwar InfluxDB installiert, aber viel weiter bin ich immer noch nicht: Mit "localhost:8086" bekomme ich nur 404 - page not found. Habe die config gecheckt, ob da ein anderer Port eingestellt ist, aber 8086 ist korrekt für http.
Was mache ich falsch????
Nun ist zwar InfluxDB installiert, aber viel weiter bin ich immer noch nicht: Mit "localhost:8086" bekomme ich nur 404 - page not found. Habe die config gecheckt, ob da ein anderer Port eingestellt ist, aber 8086 ist korrekt für http.
Was mache ich falsch????
Diesen Artikel kommentieren:
Hinweis:
- Nur Fragen / Antworten direkt zum Artikel
- Kein Support für andere Hard- oder Software !

Spamfreies E-Mail Abo nur bei neuen Artikeln
