
deepseek lokal auf Windows / macOS oder Linux installieren und benutzen
 geschrieben von Stefan, zuletzt aktualisiert am
geschrieben von Stefan, zuletzt aktualisiert am



Jeder hat sicherlich den Hype über die neue deepseek KI mitbekommen. Diese stammt aus China und wurde angeblich mit deutlich weniger Ressourcen erstellt als die US-Rivalen wie ChatGPT von OpenAI, liefert am Ende aber ähnliche Ergebnisse wie das aktuellste OpenAI o1 Modell welches Ende 2024 veröffentlicht wurde.
Angeblich schreibe ich weil ich persönlich viele der Aussagen (Entwicklungskosten kleiner 10 Millionen USD) nicht glaube. Es verdichten sich die Hinweise, dass ein Konsortium hinter dem chinesischen Startup deepseek bis zu 50.000 H100 GPUs von NVIDIA über SuperMicro in Singapur bezogen haben soll und damit die US-Sanktionen für diese Grafikkarten scheinbar erfolgreich umgangen hat. Aber darum soll es in diesem Artikel nicht gehen.
Was macht deepseek also so besonders ? Der Hauptpunkt ist meiner Meinung nach, das deepseek-r1 komplett OpenSource ist und die Sprachmodelle von Alibaba (Qwen) sowie Meta/Facebook (Llama bzw. Large Language Model Meta AI) nutzt. Beide Sprachmodelle sind Open-Source, zumindest in weiten Teilen. Qwen ist aktuell in Version 2.5 mit bis zu 72 Milliarden Parametern verfügbar, Metas LLama beherrscht für lokale Umgebungen bis zu 70 Milliarden Parameter. Die professionellen Serverversionen gehen darüber weit hinaus, benötigen dann aber mindestens 420 GB an Grafikspeicher.
Das bedeutet, dass deepseek-r1 zunächst auf lange verfügbare Sprachmodelle von Alibaba bzw. Meta aufsetzt. Darüber sitzt mit der deepseek LLM ein künstliches Sprachmodell, welches von deepseek an die eigenen Bedürfnisse angepasst wurde. Ein Sprachmodell kann man sich ähnlich wie eine Datenbank vorstellen, allerdings deutlich komplexer denn ein Sprachmodell enthält viel mehr als nur reine Daten sondern zusätzlich z.B. komplexe Algorithmen und Logiken.
Die Anzahl der Parameter bei Sprachmodellen gibt an, wie viele Verbindungen im jeweiligen neuronalen Netzwerk existieren. Sie bestimmt maßgeblich die Komplexität, Kapazität und Leistung des Modells. Eine hohe Anzahl an Parametern erfordert allerdings auch mehr Hardware zur Ausführung. Das Qwen-32B Modell etwa benötigt je nach Quantisierung zwischen 16 -64 GB an Grafikspeicher, während das LLama-70B zwischen 40-140 GB an lokalem Grafikspeicher benötigt.
Durch die so genannte Quantisierung kann der Speicherbedarf reduziert werden, dabei wird der Speicherbedarf durch eine Reduzierung der numerische Präzision der Sprachmodelle von FP16 (einfache Präzision) auf INT 8 oder INT4 verringert. Dadurch verringert sich zwar die Leistung des Sprachmodells, man erzielt aber in der Regel bessere Ergebnisse als mit einem kleineren Basismodell.
Das Qwen-32B Modell lässt sich so auf einer Grafikkarte mit 16 GB Grafikspeicher ausführen, sofern die Genauigkeit auf INT4 reduziert wird. Nur dadurch lässt sich ein so großes Modell noch lokal ausführen. Es gibt aber auch kleinere Modelle für leistungsschwächere Hardware, die Ergebnisse sind dann aber deutlich schlechter. Wer das normale ChatGPT kennt, wird sicherlich kein allzu kleines Sprachmodell verwenden wollen.
Installation von deepseek-r1 mit qwen/llama über Ollama
Mit Ollama gibt es ein kleines Tool, mit dem sich aktuelle LLM (Large Language Modells) sehr einfach lokal ausführen lassen. Es werden die Betriebssysteme Windows 10/11, Linux und macOS 11+ unterstützt.
Ist das Tool installiert, findet man auf der Ollama deepseek-r1 Modellseite eine Auflistung der unterstützen Sprachmodelle und den Befehl, wie man diese installiert bzw. ausführt. Das Ganze ist ein Text-Only Chatbot, welcher im Fall von Windows über die PowerShell angesprochen wird.
Um deepseek-r1 nun lokal nutzen zu können, muss zunächst ein aktuelles Sprachmodell wir Qwen oder Llama heruntergeladen werden. Das kann man vereinfacht als Datenbank verstehen, welche deepseek-r1 nutzt um auf Fragen zu antworten. Einen expliziten Installationsbefehl gibt es nicht, Ollama weiß beim Aufruf eines Modells ob dieses bereits lokal heruntergeladen wurde oder nicht. Bei erstmaliger Nutzung startet der Download automatisch. Dieser ist sehr hakelig und setzt sich gerne mal zurück.
Mein Tipp: einfach Laufen lassen, irgendwann ist der Download dann erfolgreich. Das kann aber auch aufgrund der aktuell sehr hohen Anfrage etwas dauern.
Um exemplarisch das Sprachmodell Qwen-14B (ca. 8 GB Grafikspeicher bei INT4 bzw. 16 GB Grafikspeicher bei INT8) aufzurufen und herunterzuladen gebt ihr in die Windows Powershell (bzw. bei macOS / Linux im Terminal) folgenden Befehl ein:
ollama run deepseek-r1:14b

Ihr könnt nacheinander beliebig viele Sprachmodelle herunterladen und ausführen, denkt aber bitte daran, dass ihr die dementsprechende Hardware haben müsst. Für die besseren Sprachmodelle mit mindestens 32B Parametern sind das mindestens 16 GB Grafikspeicher bzw. ein Apple mac mit M-Prozessor und mindestens 24 GB gemeinsamen Speicher.
Das menschliche Denken
Eine Neuheit der aktuellen Sprachmodelle von Llama und Qwen ist das so genannte menschliche Denken. Dieses soll die Ergebnisse deutlich verbessern denn das Sprachmodell kann teilweise auch Fragen beantworten auf welche es gar nicht explizit trainiert wurde. Die Antworten werden dann durch einen simulierten Denkprozess erschlossen, so wie es auch ein Mensch machen würde wenn er nicht die direkte Antwort kennt, wohl aber Hintergründe zu dieser Frage und Wissen rund um die direkte Antwort.
Dieses Denken wird in Ollama in einem "think" Bereich angezeigt, der erläutern soll wieso der ChatBot eine bestimmte Antwort gibt. Anschließend folgt dann die eigentliche Antwort. Gefragt habe ich deepseek-r1 nach der tiefsten Stelle des Mittelmeeres:
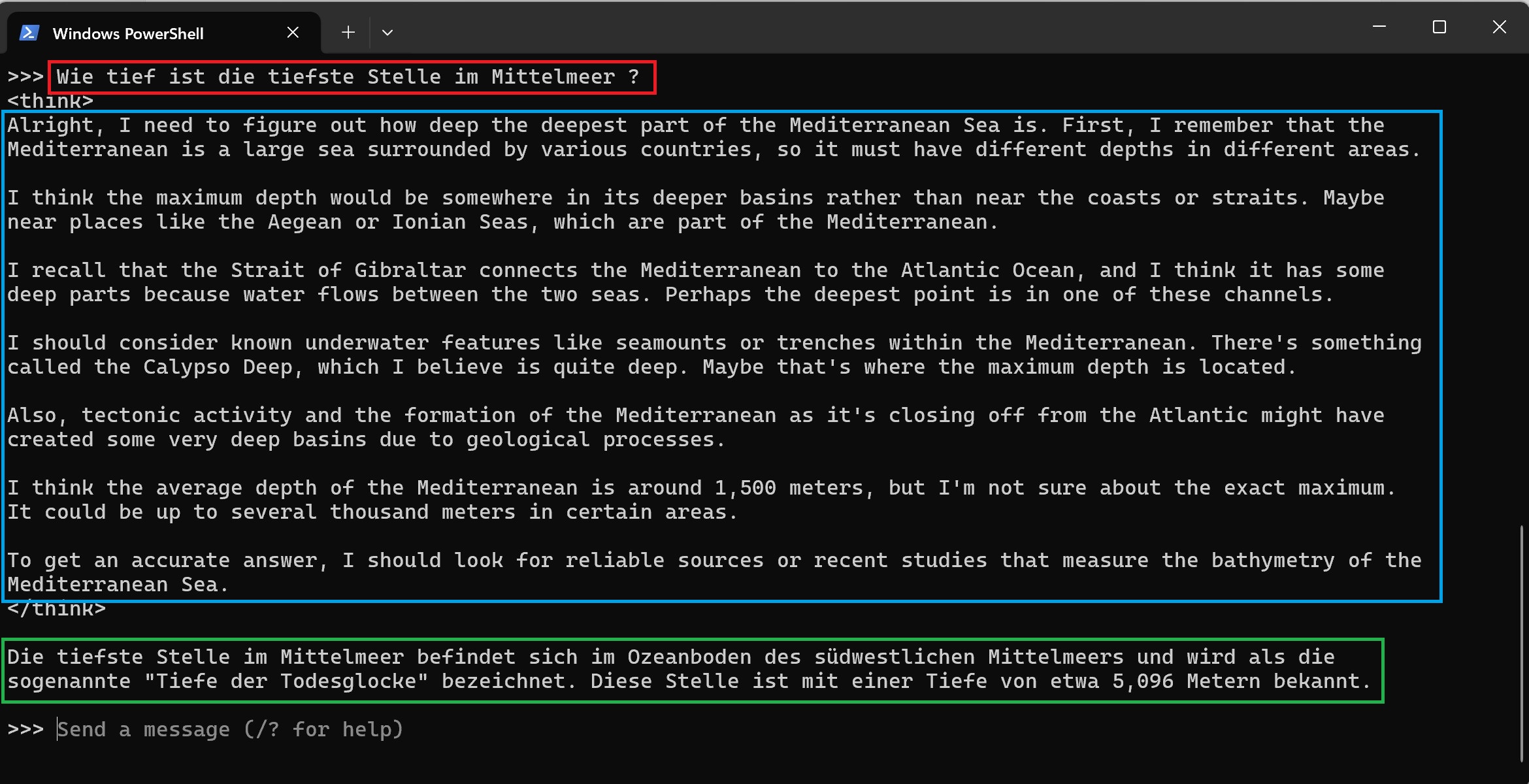
Die Antwort von deepseek-r1 ist 5.096 Meter, was relativ dicht an den korrekten 5.109 Metern (Calypsotiefe) liegt welche im Ionischen Becken liegt.
Meine zweite Frage fordert meine RTX 4070 Ti Super etwas, denn diese heult kurz auf. Ich möchte die Zahl Pi mit 100 Nachkommastellen wissen:
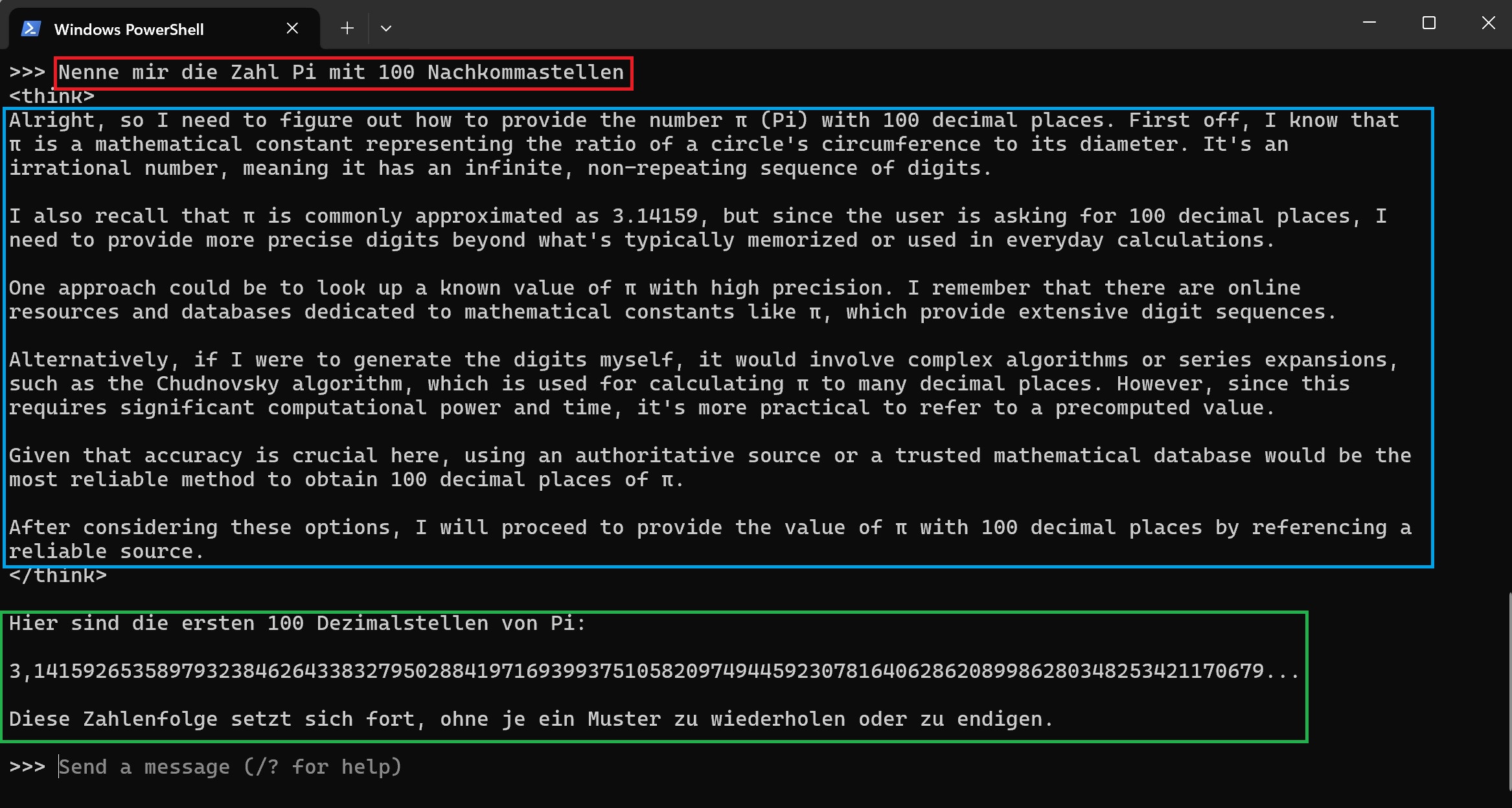
Die korrekte Antwort konnte mir deepseek-r1 dann aber schon nach 1-2 Sekunden liefern. Der Datenstand von deepseek-r1 liegt beim Qwen-14B Sprachmodell mit Oktober 2023 übrigens schon etwas zurück. Die deutsche Sprache beherrscht deepseek-r1 auf den ersten Blick ganz gut, auch wenn der ChatBot ab und zu Antworten auf Englisch oder sogar Chinesisch gibt. "Denken" tut deepseek-r1 aktuell wohl nur auf Englisch oder Chinesisch.

Fazit
Mit Ollama ist es ziemlich einfach lokal deepseek-r1 auszuführen. Gerade für die größeren Sprachmodelle benötigt man aber dementsprechende Ressourcen. Die Qualität der Antworten fand ich schon beim 14B-Modell recht gut, welches 8 GB Grafikspeicher oder ca. 12 GB gemeinsamen Speicher (Apple M) benötigt.
Das 32B Modell benötigt mindestens 16 GB Grafikspeicher (24 GB Apple M) und ist qualitativ nochmal ein ganzes Stück besser. Die richtig großen Modelle laufen dann nur auf professioneller Hardware. Das Llama 70B Sprachmodell benötigt mindestens 40 GB Grafikspeicher, also zwei RTX 4090 oder einem Apple M Prozessor mit mindestens 48 GB gemeinsamen Speicher.
Bei Links, die mit einem * gekennzeichnet sind, handelt es sich um Affiliate-Links, bei denen wir bei einem Kauf eine Vergütung durch den Anbieter erhalten.
Kommentare (2)

Johann
 08.03.2025
08.03.2025
Ich bekomme heute oder Montag endlich eine Grafikkarte mit 16GB VRAM (Asus RX 9070 Prime Gaming). Vielleicht teste ich auch mal deepseek oder Ähnliches. Dank deiner ausführlichen Anleitungen könnte es gelingen.
ShadowI
02.02.2025
Vielen Dank! Auch für die Klarstellung, daß man offenbar nicht mit "wget" sich erst einmal die wichtigsten Dateien lokal herunterladen kann - wenn man mehrere Installationen durchführen möchte - sondern eine Internet-Verbindung benötigt wird für das erste Herunterladen.
Diesen Artikel kommentieren:
Hinweis:
- Nur Fragen / Antworten direkt zum Artikel
- Kein Support für andere Hard- oder Software !

Spamfreies E-Mail Abo nur bei neuen Artikeln
