
Apple Mac mini als lokaler KI-Server in deinem Netzwerk
 geschrieben von Stefan, zuletzt aktualisiert am
geschrieben von Stefan, zuletzt aktualisiert am



Die Welt der künstlichen Intelligenz entwickelt sich rasant – und mit ihr die Möglichkeiten, solche Technologien auch abseits großer Cloud-Plattformen zu nutzen. Inzwischen ist es durchaus machbar, leistungsstarke Sprachmodelle direkt auf dem eigenen Computer zu betreiben. Wer einen Mac mini mit Apple Silicon Prozessor (M1, M2, M3 oder M4) besitzt, kann damit erstaunlich weit kommen. In dieser ausführlichen Anleitung lernst du, wie du mit Tools wie Ollama und OpenWebUI moderne KI-Sprachmodelle (Large Language Models bzw. zukünftig in diesem Artikel nur LLMs genannt) lokal zum Laufen bringst.
Warum überhaupt ein lokales Sprachmodell verwenden?
Immer mehr Menschen setzen auf lokale Lösungen, wenn es um KI-Anwendungen geht. Und das hat gute Gründe. Cloud-Dienste sind bequem, keine Frage – aber sie bringen auch gewisse Abhängigkeiten mit sich: laufende Kosten, Datenschutzbedenken, manchmal auch Performance-Einschränkungen. Wer sensible Daten verarbeitet, experimentieren will oder schlicht die volle Kontrolle über das Verhalten seiner Tools behalten möchte, wird mit einer lokalen Installation deutlich glücklicher sein.
Hinzu kommt: neuere Mac mini mit M1, M2, M3 oder M4 Prozessoren sind in der Lage, LLMs effizient zu verarbeiten. Und mit Lösungen wie Docker, Ollama oder OpenWebUI ist der Einstieg so einfach wie nie. In dieser Anleitung achte ich vor allem auf einen hohen Bedienkomfort. Das bedeutet, dass Du später per Browser oder FakeApp (dazu später mehr) direkt von allen deinen Geräten wie Smartphone, Tablet oder Computer bequem auf deine lokale KI zugreifen kannst.
Voraussetzungen: Was dein Mac können sollte
Diese Anleitung ist für einen Einstiegs Mac mini mit dem Apple M4 Prozessor und 16 GB gemeinsamen Speicher geschrieben, kann aber auch auf anderer Apple Hardware (z.B. einem MacBook Air oder MacBook Pro) verwendet werden. Zuerst aber eine Information: richtig gut sind lokale LLMs erst, wenn deine Hardware ausreichend Grafikspeicher besitzt. Bei den M-Prozessoren ist dies der gemeinsame Speicher, den sich Prozessor und Grafikkarte teilen.
Kleinere LLMs laufen bereits auf Macs mit 8 GB Speicher, aber ich empfehle dringend einen Mac mit mindestens 16 GB gemeinsamen Speicher. Je mehr Speicher, desto schneller antwortet deine lokale KI und um so größere Sprachmodelle kannst Du benutzen. Je größer ein Sprachmodell ist, desto schlauer ist deine KI bzw. desto mehr Informationen stehen der KI zur Verfügung.
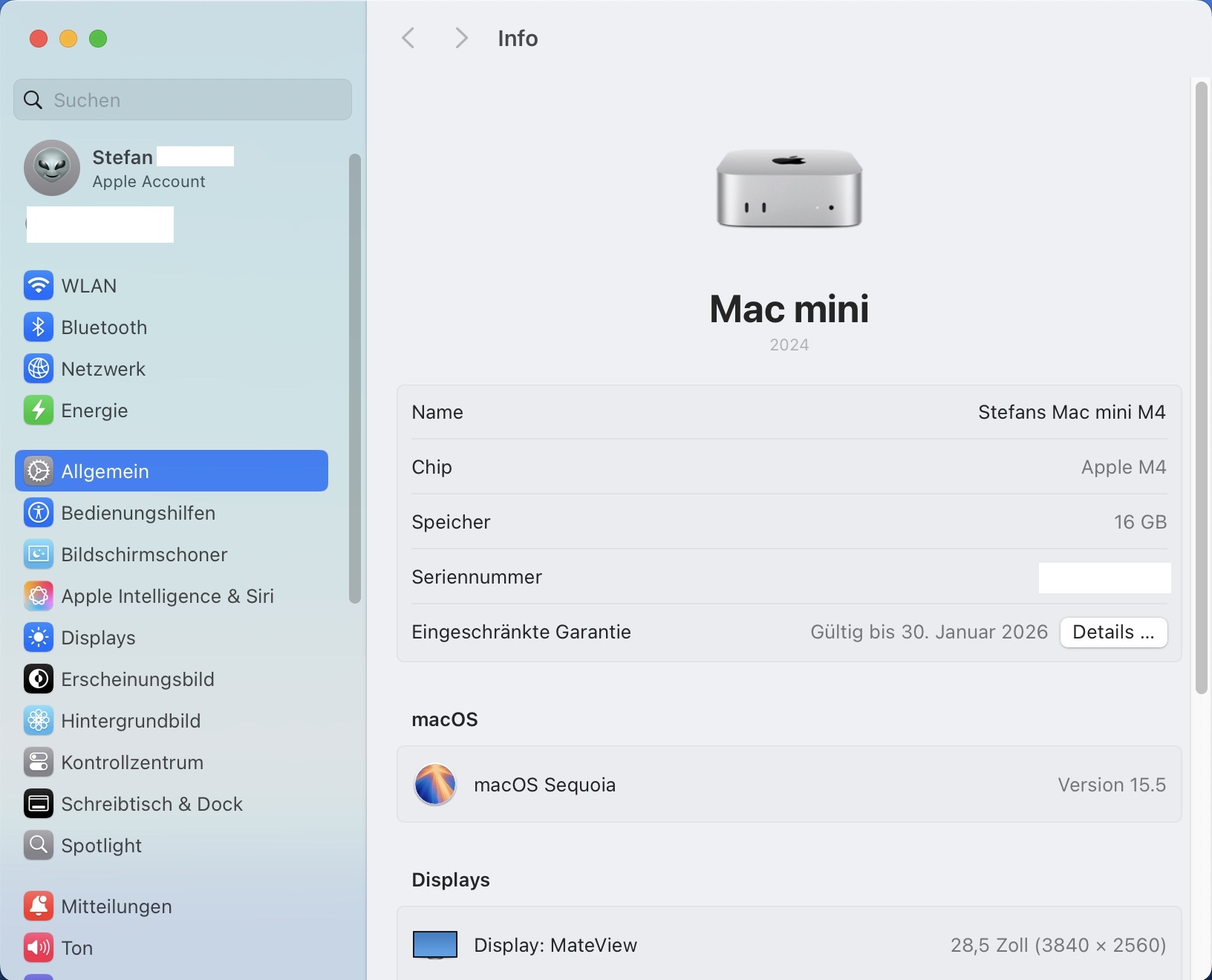
Ideal sind meiner Meinung nach aktuell Macs mit 24 GB oder mehr an gemeinsamen Speicher. Richtig große und moderne Sprachmodelle wie Metas LLama 3.3 mit 70 Billionen Parametern benötigen ca. 34 GB an Speicher. Da dieser Speicher dann nicht mehr deinem restlichen System zur Verfügung steht, müsste dein Mac idealerweise schon mit 48 GB gemeinsamen Speicher ausgestattet sein. Zum Testen habe ich unter anderen einen Apple Mac mini M4 - 16 GB * Speicher benutzt, der lief z.B. mit Microsofts neuem Phi4-Sprachmodell gut. Preislich liegt dieser Mac mit 600 Euro auch in einem bezahlbaren Bereich.
Fast doppelt so schnell in KI-Anwendungen ist der Apple Mac mini M4 Pro - 24 GB *, allerdings kostet dieser mit 1450 Euro auch mehr als doppelt so viel wie die Einstiegsvariante. Persönlich nutze ich ein Apple 2024 MacBook Pro M4 Pro 24 GB *, welches mit 2000 Euro nochmal teurer ist, dafür aber natürlich ein komplettes System mit Bildschirm usw. darstellt.
Was dein Mac benötigt
- Apple M1/M2/M3/M4 Prozessor
- 16 GB oder mehr an gemeinsamen Speicher
- macOS 15 (Sequoia)
Apples M-Prozessoren besitzen eine integrierte Grafikkarte. Je mehr GPU-Kerne diese hat, desto schneller ist diese innerhalb einer Generation. Außerdem integrieren diese Prozessoren die Apple Neural Engine, ein Bereich innerhalb der CPU der auf KI-Verarbeitung spezialisiert ist. Je moderner der Prozessor, desto schneller ist die KI-Leistung und damit die Geschwindigkeit mit der die lokale KI deine Anfragen beantwortet.
Hauptaugenmerk sollte aber wie beschrieben bei der Menge des gemeinsamen Speichers liegen, damit das lokale LLM komplett im Speicher liegt. Muss dein System Daten aus dem Speicher auf die SSD verschieben, sinkt die Antwortgeschwindigkeit rapide oder die Ausführung der lokalen LLM funktioniert gar nicht. Es gibt hier quasi keine Begrenzung: je mehr gemeinsamer Speicher, desto besser. Als zweites Hardware-Merkmal beeinflusst die Speicherbandbreite die Geschwindigkeit, in der das System KI-Anfragen beantwortet.
Hier meine persönliche Einschätzung der KI-Geschwindigkeit aktueller Apple M-Prozessoren:
- Apple M3 Ultra - 818 GB/s (~ RTX 4070 Ti)
- Apple M4 Max - 410 GB/s (~ RTX 4070)
- Apple M4 Pro - 273 GB/s (~ RTX 4060)
- Apple M4 - 120 GB/s (~ RTX 3050)
Die neuen Apple M4 bzw. Apple M4 Pro Prozessoren sind ideal für textbasierte KI geeignet. Die blauen Links führen zu unserer CPU-Vergleichsseite CPU-Monkey, auf der ihr die Leistung der einzelnen Prozessoren ansehen und vergleichen könnt.
Die Geschwindigkeit, mit der Anfragen an das Sprachmodell verarbeitet werden, hängt insbesondere von der Speichergeschwindigkeit ab, die beim Apple M4 bei 120 GB/s liegt. Der Apple M4 PRO kommt bereits auf 273 GB/s und der Apple M4 Max kommt auf 410 GB/s. Zum Vergleich: meine NVIDIA GeForce RTX 4070 Ti Super kommt auf 672 GB/s und ist damit ca. 5,6x so schnell wie der Apple M4, was bei Messung der benötigten Antwortzeit (Token/s) auch ungefähr hinkommt.
Schritt 1: Stelle sicher, dass macOS aktuell ist
Auch wenn es banal klingt – ein aktuelles Betriebssystem verhindert viele unnötige Stolperfallen. Neue Features, Sicherheits-Updates oder schlicht aktuelle Bibliotheken können entscheidend sein.
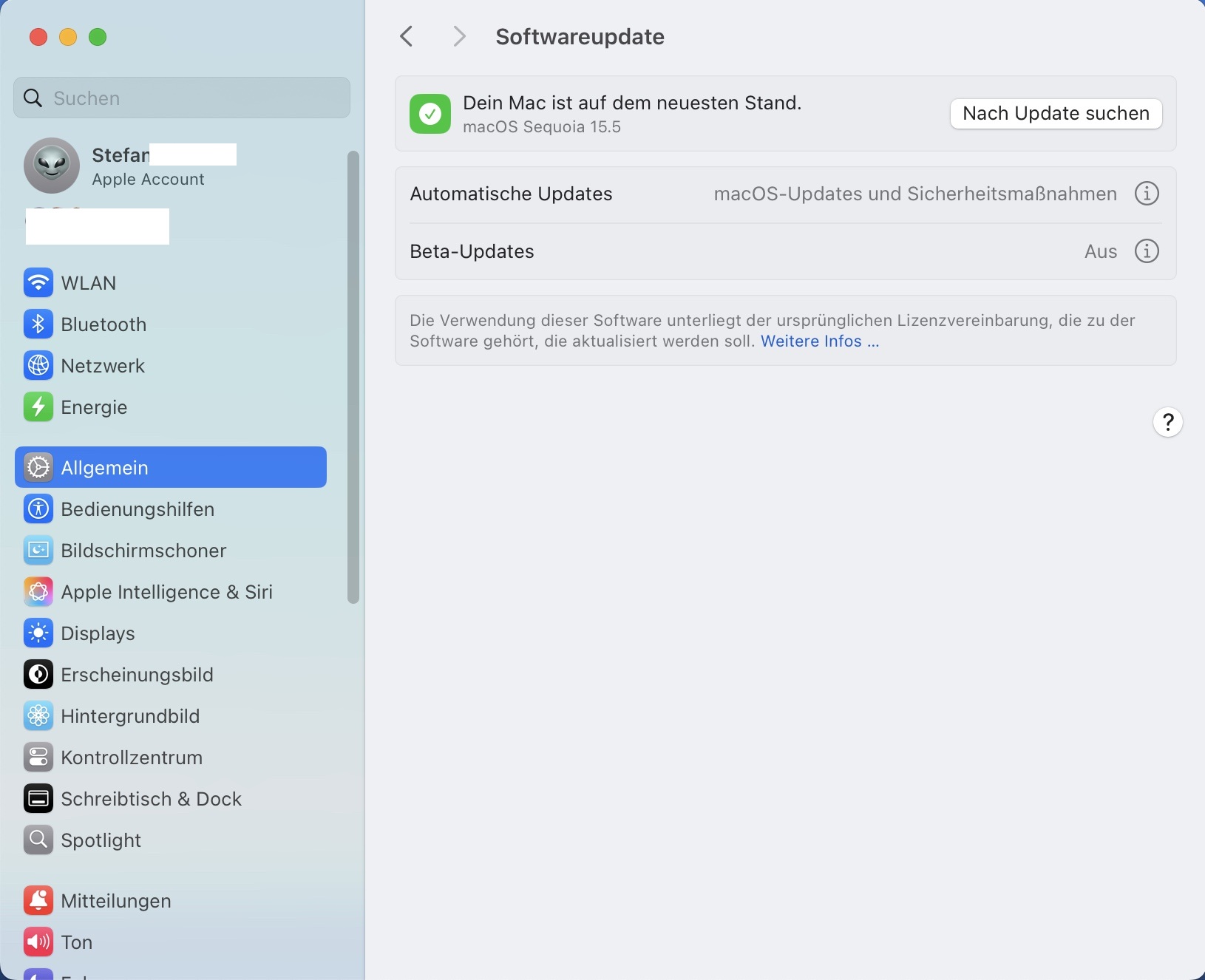
Gehe dazu in die Systemeinstellungen, wähle Allgemein > Softwareupdate und prüfe, ob dein System aktuell ist. Nach einem Update solltest du den Mac neu starten.
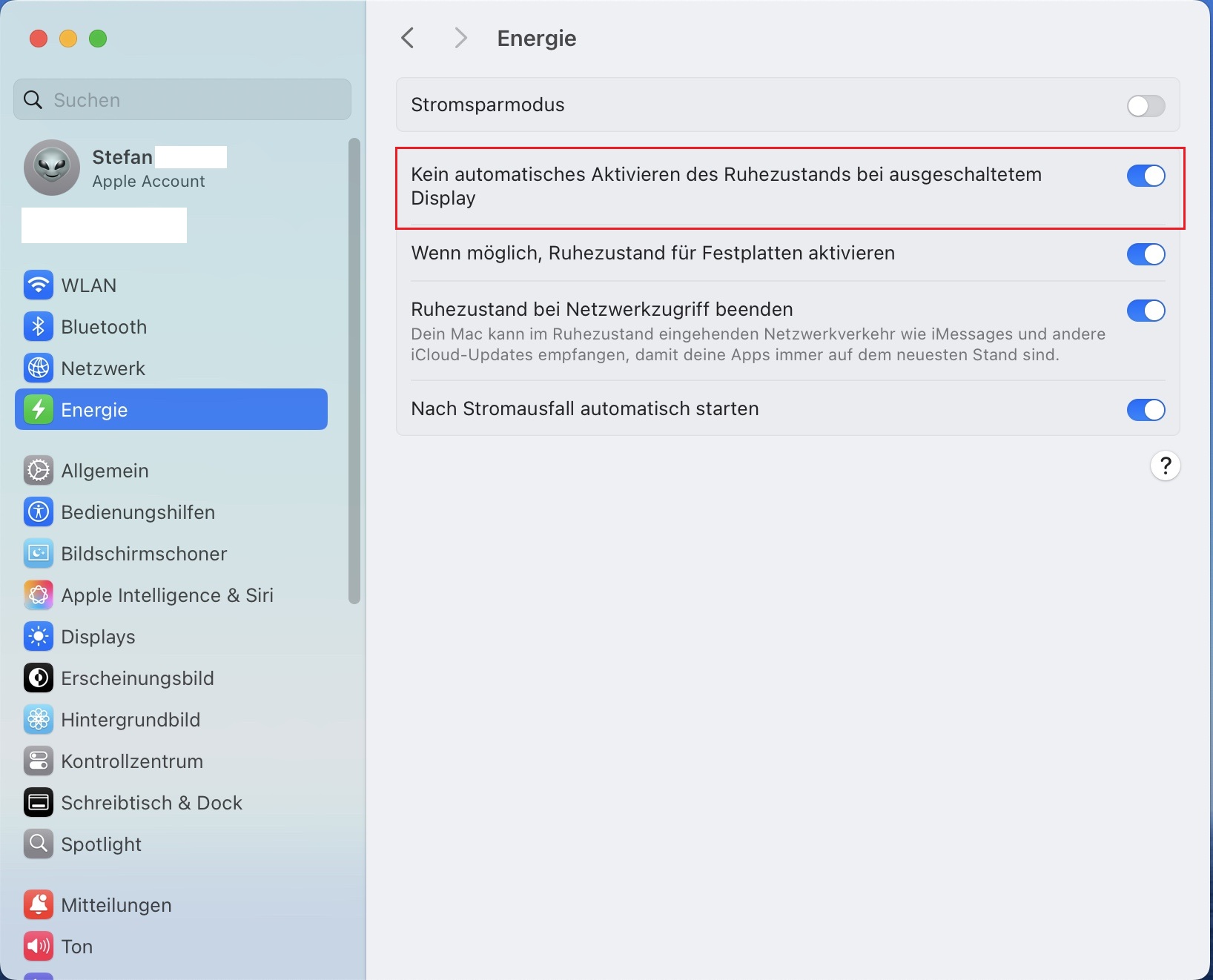
Zusätzlich solltest Du auf deinem Mac die Energieeinstellungen prüfen, damit dein Mac nicht in den Ruhezustand wechselt. Ansonsten ist die Weboberfläche der lokalen KI nicht für andere Geräte im Netzwerk erreichbar, sobald dein Mac in den Standby (Ruhezustand) wechselt.
Schritt 2: Ollama installieren – der Kern der LLM-Verwaltung
Ollama ist eine Software, die speziell dafür entwickelt wurde, große Sprachmodelle lokal zu betreiben – schnell, zuverlässig und benutzerfreundlich. Die Installation ist sehr einfach. Lade dir zunächst die neuste Ollama Version für deinen Mac direkt von der Herstellerseite herunter. Das Disk-Image (.dmg) ziehst Du nach dem Download in deinen Programme Ordner (Finder). Starte anschließend Ollama einmalig, um die Grundkonfiguration abzuschließen. Mehr ist erst mal nicht nötig. Ollama wird später im Hintergrund laufen, sobald du ein Modell startest.
Schritt 3: Modelle laden und verwalten
Das Herzstück jeder LLM-Nutzung sind die Sprachmodelle selbst. Sie enthalten all das „Wissen“, das in der KI steckt. Ollama kann Sprachmodelle selbst herunterzuladen. Dazu öffnest Du das Terminal (Spotlight: Cmd + Leertaste > "Terminal") und gibst "ollama pull
Welches Sprachmodell Du verwenden möchtest, liegt dabei ganz bei dir. Es sollte aber auf die Hardware deines Macs abgestimmt sein. Viele Sprachmodelle gibt es in verschiedenen Ausführungen bzw. Größen. Die Größe eines Sprachmodells wird in Billionen-Parametern angegeben, also z.B. "14b" entsprechen 14 Billionen Parametern. Als grobe Faustformel gilt: die Dateigröße des gewählten Sprachmodells sollte die Größe deines gemeinsamen Speichers nicht überschreiten.
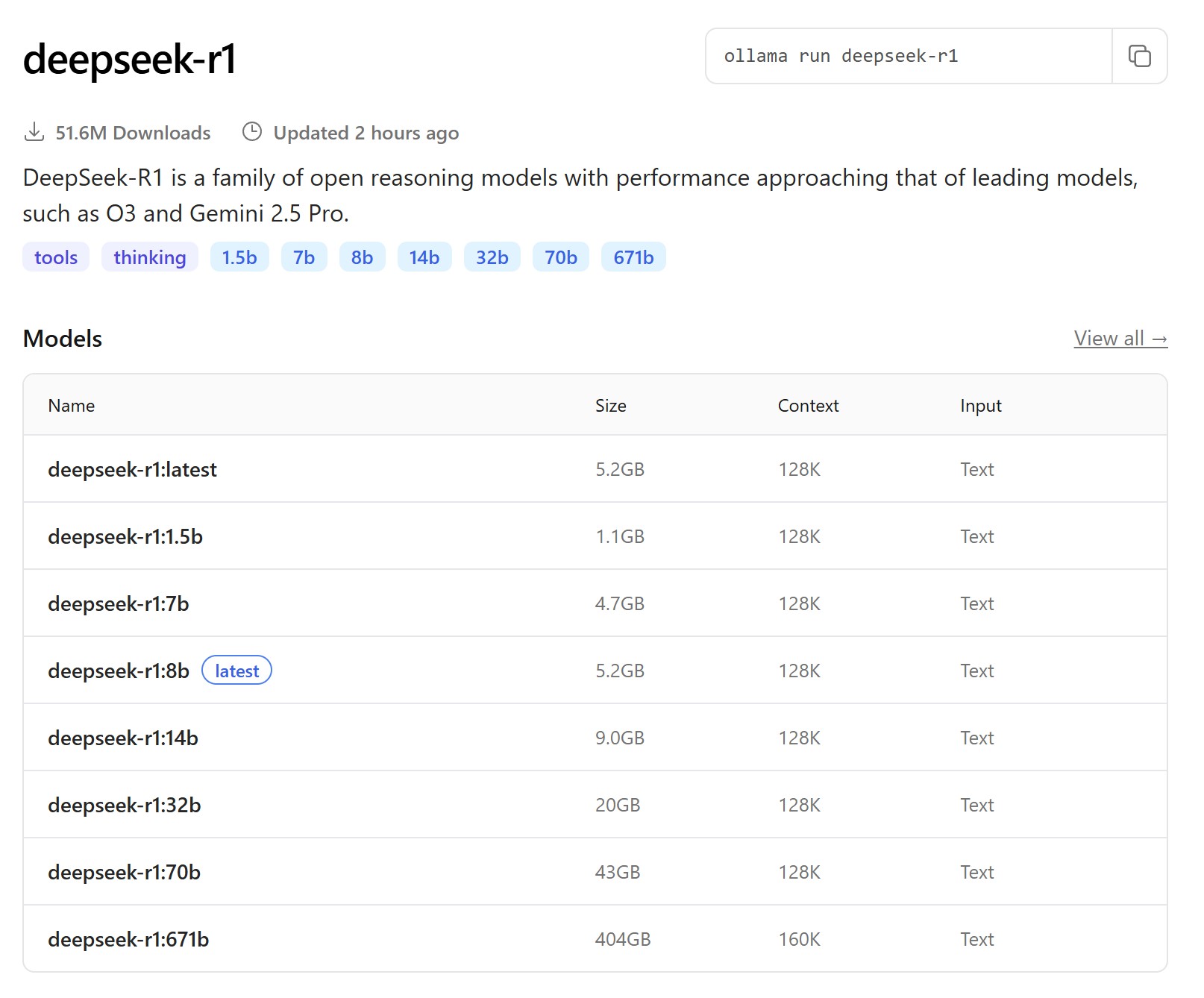
Als Entscheidungshilfe habe ich dir diese Tabelle für Macs mit M-Prozessor erstellt. Der benötigte gemeinsame Speicher muss immer etwas größer ausfallen als der für das Sprachmodell benötigte Grafikspeicher, da dein Grundsystem etwas Speicher als Arbeitsspeicher reserviert. Idealerweise benötigt das Sprachmodell nicht mehr als 2/3 deines gesamten gemeinsamen Speichers.
| Modellgröße | Grafikspeicher | Gemeinsamer Speicher |
| 8B | ab 6 GB | 8 GB |
| 14B | ab 8 GB | 16 GB |
| 32B | ab 16 GB | 24 GB |
| 70B | ab 34 GB | 48 GB |
Hier nun eine Auswahl an Sprachmodellen die Du über das Terminal herunterladen kannst:
ollama pull phi4 ollama pull llama3.1 ollama pull deepseek-r1:14b ollama pull llama3 ollama pull llama3.3 ollama pull deepseek-r1:8b ollama pull deepseek-r1:32b ollama pull qwen3:32b
Erklärung der KI-Sprachmodelle
Phi4 ist ein modernes Sprachmodell von Microsoft, dass auf kleinere Systemen mit nur 8 GB Grafikspeicher optimiert ist. Es liefert für seine geringe Größe sehr gute Ergebnisse und ist ideal zum Einstieg. LLaMA3 ist das aktuelle Sprachmodell von Meta und eine Weiterentwicklung der bekannten LLaMA-Reihe. Es ist komplett Open-Source und ist in verschiedenen Größen verfügbar. DeepSeek-R ist ein leistungsstarkes chinesisches Open-Source-Modell, das zunehmend an Bedeutung gewinnt. Qwen3 stammt von Alibaba und ist auf mehrsprachige Fähigkeiten ausgerichtet.
Es stehen verschiedene Modelle zum Download zur Verfügung. Neben reinen Sprachmodellen ähnlich wie ChatGPT gibt es auch Modelle, die auf besondere Fähigkeiten wie Bilderkennung oder Programmierung optimiert sind. Welche Du benutzen möchtest, hängt alleine von dir ab.
Schritt 4: Docker Desktop einrichten
Nachdem Du ein oder mehrere Sprachmodelle heruntergeladen hast, kann es weitergehen. Wir wollen unsere lokale KI später via Webbrowser benutzen. Das sieht nachher ungefähr so aus wie ChatGPT. Dafür nutzen wir die kostenlose Software OpenWebUI. Auf Wunsch kann der Mac damit komplett "headless" betrieben werden. Das bedeutet, dass an dem Mac kein Bildschirm und keine Eingabegeräte wie Maus oder Tastatur angeschlossen werden müssen.
Das funktioniert bei eingeschalteter FileVault-Festplattenverschlüsselung allerdings nur bis zum nächsten Neustart, da danach das Anmeldepasswort manuell eingegeben werden muss. Diese Eingabe lässt sich aus Sicherheitsgründen aktuell auch nicht überspringen. Ihr müsst euch hier also entscheiden ob ihr FileVault aktiviert lasst oder nicht. Bei deaktiviertem FileVault ist ein headless-Betrieb möglich.
Um OpenWebUI nutzen zu können, brauchst du Docker – eine Plattform für Container-Anwendungen. Keine Angst: Docker Kenntnisse sind nicht erforderlich und wir nutzen zudem Docker Desktop, ein Programm mit einer übersichtlichen Bedienoberfläche. OpenWebUI wird später isoliert in deinem Docker Container laufen. Das ist einfach und auch sicher, denn die Weboberfläche ist später aus deinem Netzwerk erreichbar.
Lade dir Docker Desktop für Mac mit Apple Silicon Prozessor herunter und installiere es. Aktiviere die nötigen Systemerweiterungen, wenn du gefragt wirst. Das ist notwendig, damit Docker auf dein System zugreifen kann und es keine Fehler im Betrieb gibt. Nach der Einrichtung sollte Docker automatisch im Hintergrund laufen.
Schritt 5: OpenWebUI installieren und starten
Mit OpenWebUI bekommst du eine einfache, aber mächtige Benutzeroberfläche, über die du deine lokalen Modelle bedienen kannst. Diese wird als Container direkt in deiner Docker Umgebung installiert. Das geht ganz einfach über einen Befehl, den Du wieder über dein Terminal eingibst:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
Dieser Befehl erstellt einen Docker Container mit dem Namen Open-WebUI, läd das Programm (Image) herunter und startet anschließend den Dienst. Es sorgt außerdem dafür, dass der Container beim Neustart des Systems automatisch wieder aktiv ist.
Kontrolliere im Anschluss über die Docker Desktop Oberfläche, dass dein OpenWebUI Container läuft:
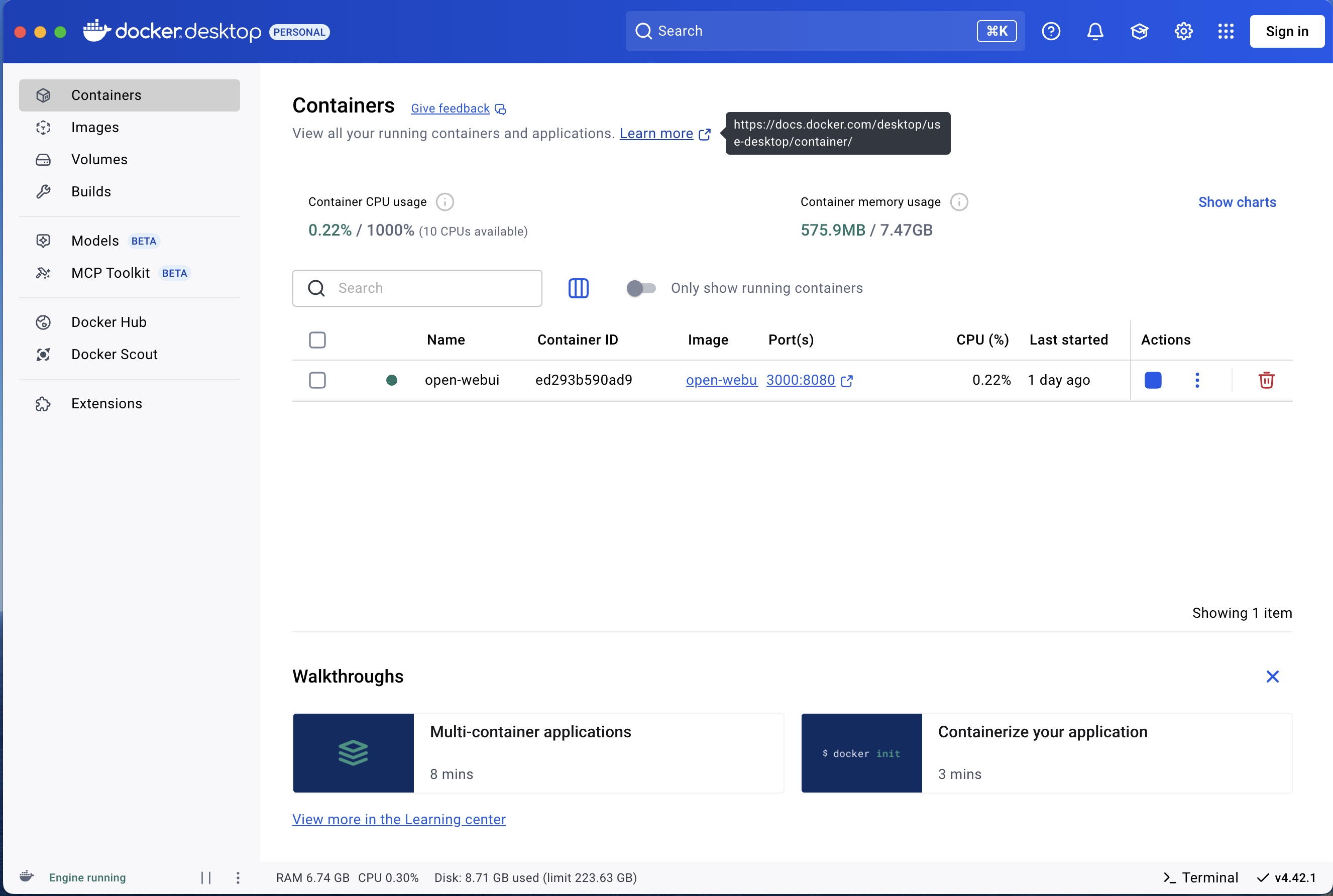
Schritt6: Oberfläche im Browser öffnen
Öffne jetzt deinem Browser und gehe zu: http://localhost:3000. Beim ersten Start von OpenWebUI musst Du dir nun ein Benutzerkonto anlegen, welches automatisch Administrator-Rechte erhält. Anschließend kannst Du bereits mit deinem lokalen KI-Sprachmodell arbeiten. Welche Modelle dir zur Verfügung stehen, kannst Du oben links sehen (bei mir im Bild phi4).
Du kannst beliebig viele verschiedene Sprachmodelle über Ollama herunterladen und in OpenWebUI benutzen. Da diese allerdings viel Speicherplatz benötigen, nutze ich meist nur 2-3 verschiedene Modelle.
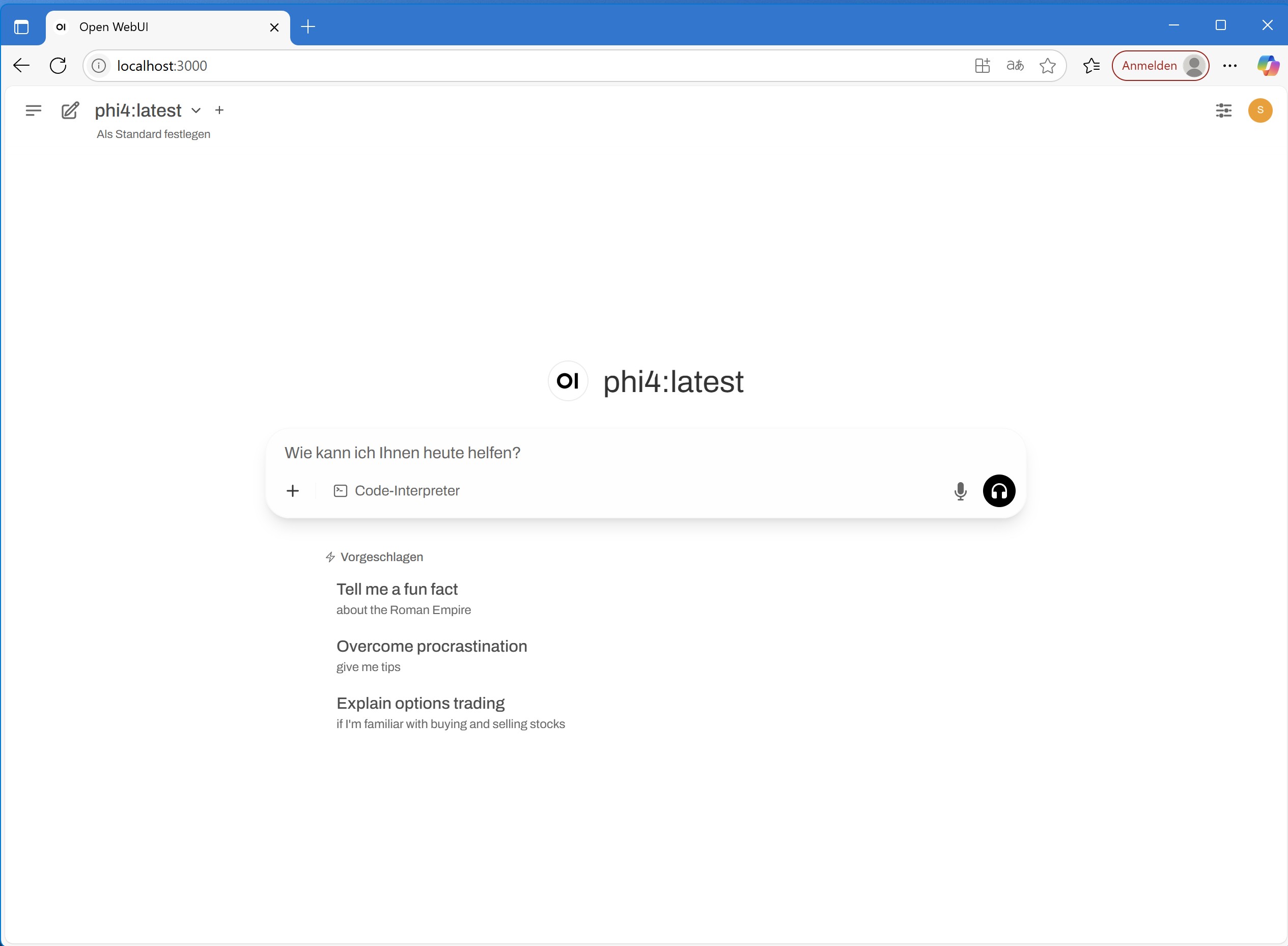
Deine KI im Netzwerk
Wir hatten bisher auf OpenWebUI über die Adresse http://localhost:3000 zugegriffen. Das funktioniert allerdings nur, solange Du dich auf dem Computer befindest, auf dem auch OpenWebUI läuft. Möchtest Du von anderen Geräten aus deinem Netzwerk auf OpenWebUI zugreifen, musst Du dieses über die öffentliche IP-Adresse deines Macs tun. Diese findest Du in den Netzwerkeinstellungen von macOS.
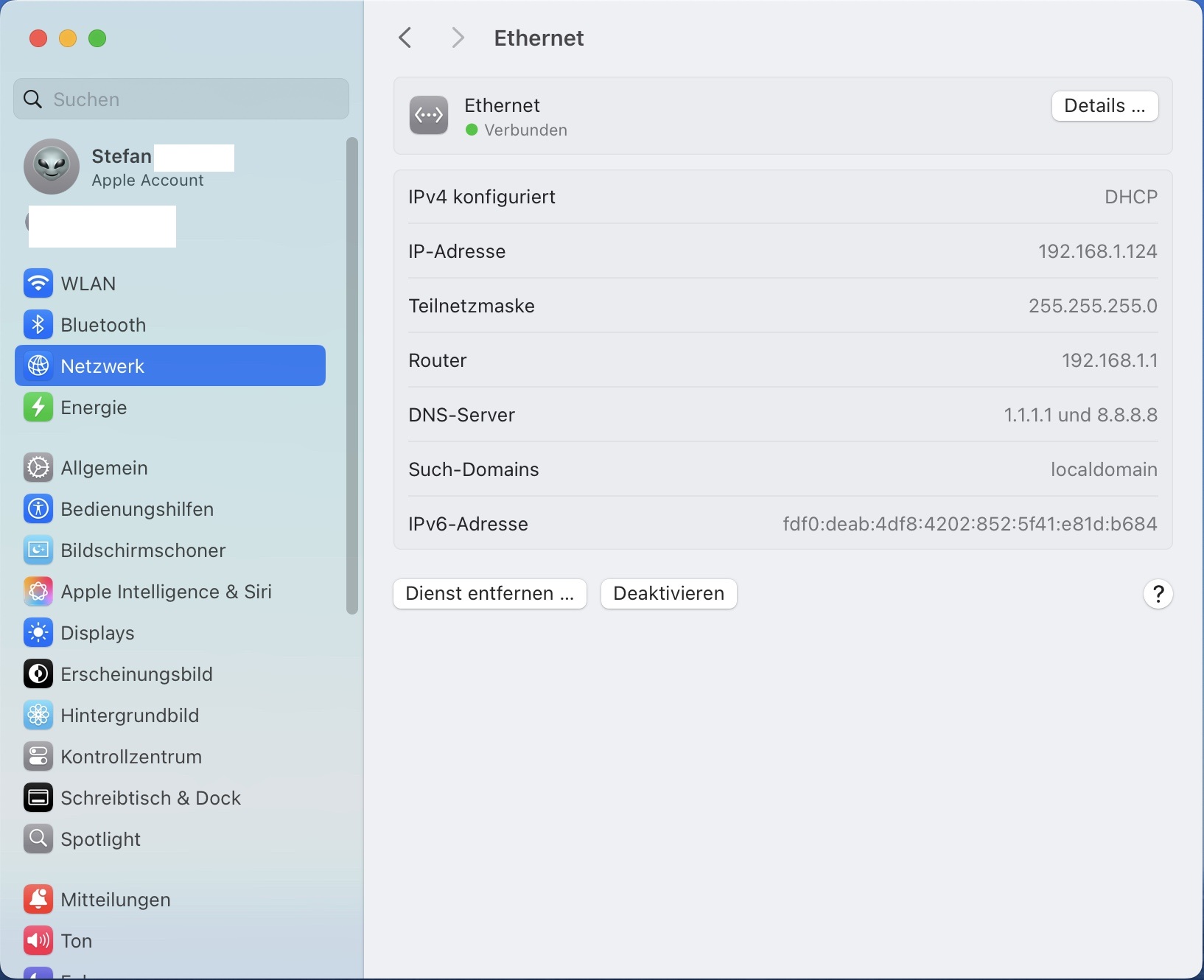
Damit deine lokale KI zuverlässig erreichbar ist, sollte dein Mac über eine statische IP-Adresse verfügen, die sich nicht ändert. Alternativ kannst Du in deinem Router dem Gerät via DHCP immer die gleiche IP-Adresse zuweisen lassen. Das können alle aktuellen Router.
Über die öffentliche IP-Adresse ist deine KI nun auch z.B. über den Browser deines Smartphones erreichbar, wenn Du zu Hause bist. Möchtest Du direkt über ein Icon auf deiner iPhone Oberfläche auf die KI zugreifen, wie bei ChatGPT, dann kannst Du dieses über die Teilen Funktion und dann zum Home-Bildschirm über den Safari Browser erstellen.
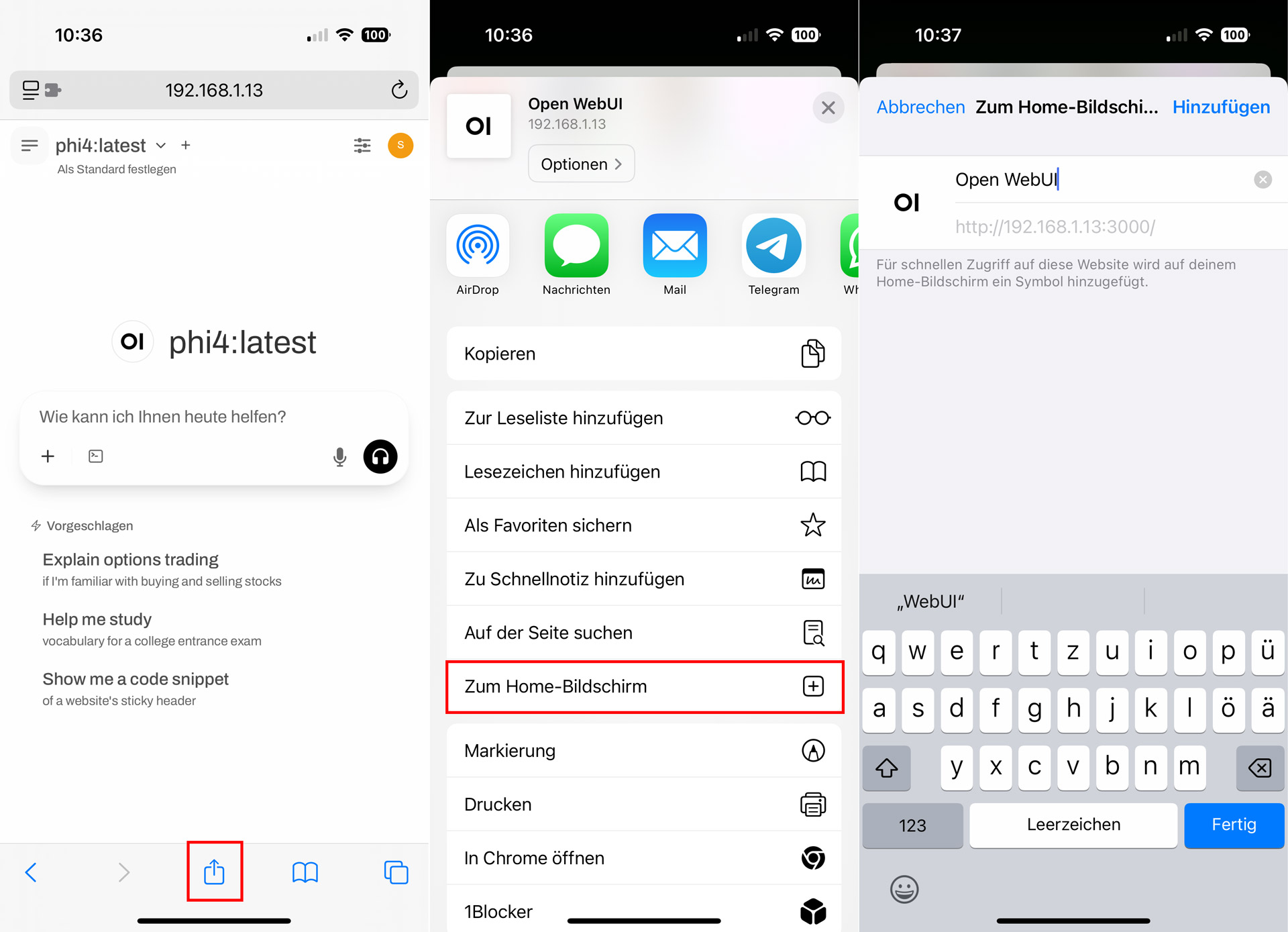
Meine lokale KI ist sogar aus dem Internet erreichbar, indem ich über einen DynDNS-Provider die Oberfläche auch extern erreichbar gemacht habe. Das würde diese Anleitung allerdings sprengen, auf Wunsch kann ich hierzu später separat eine eigene Anleitung verfassen.
Anwendungsszenarien: Wofür eignet sich eine lokale KI?
Du fragst dich vielleicht: Was kann man mit einem lokal installierten Sprachmodell eigentlich machen? Hier ein paar Ideen:
- Texte automatisch generieren (Blogposts, Zusammenfassungen, E-Mails)
- Code schreiben und erklären lassen
- Daten analysieren oder strukturieren
- Texte übersetzen oder vereinfachen
- Wissensfragen beantworten lassen – ohne Internetverbindung
Generell können die hier vorgestellten KI-Modelle nur textbasierte Antworten geben und Bild und Text interpretieren. Man kann die lokale KI-Verarbeitung aber auch auf Bild- und Videoverarbeitung erweitern. Dies mache ich bei mir aktuell mit ComfyUI. Die Bedienung erfolgt dann bequem auch aus der OpenWebUI. Wie das geht, werde ich euch in einer späteren Anleitung zeigen.
Dein Mac als persönliche KI-Zentrale
Es braucht etwas Vorbereitung, aber der Aufwand lohnt sich: Mit den richtigen Tools verwandelst du deinen Mac in eine leistungsstarke, komplett autonome KI-Zentrale. Ollama kümmert sich um die Verwaltung der Modelle, OpenWebUI macht die Bedienung kinderleicht – und du hast jederzeit die volle Kontrolle.
Gerade wer Wert auf Datenschutz legt oder ohne externe Dienste experimentieren möchte, findet hier eine moderne, flexible Lösung. Ob für die tägliche Arbeit, Hobbyprojekte oder zur Erforschung der Technik: Lokale LLMs eröffnen dir eine neue Welt. Dabei bietet der Apple Mac mini M4 - 16 GB * Speicher zu einem Preis von nur 600 Euro preislich einen guten und bezahlbaren Einstieg in die lokale KI-Welt.
Für anspruchsvollere Anwender empfinde ich den Apple Mac Studio M4 Max 64GB für 3000 Euro als eine gute Wahl, der für die Leistung auch nicht zu teuer ist. Die KI-Leistung liegt dann ca. auf dem Niveau einer RTX 4070, allerdings können rund 42 GB des gemeinsamen Speichers für die Grafik reserviert werden und das sind dann immerhin 10 GB Grafikspeicher mehr als eine NVIDIA GeForce RTX 5090 * besitzt (die mit einer Speicherbandbreite von knapp 1800 GB/s in der reinen KI-Leistung aktuell das Maß der Dinge im privaten Bereich ist).
Bei Links, die mit einem * gekennzeichnet sind, handelt es sich um Affiliate-Links, bei denen wir bei einem Kauf eine Vergütung durch den Anbieter erhalten.
Kommentare (3)

Knut
 12.03.2026
12.03.2026
Hat bei mir auch super funktioniert. Danke. Mac Mini M4 Pro.
Allerdings hat Open-WebUI noch ein paar Probleme bei mir mit dem Wissensspeicher. Bin gerade dabei das mit qdrant so lösen.
Allerdings hat Open-WebUI noch ein paar Probleme bei mir mit dem Wissensspeicher. Bin gerade dabei das mit qdrant so lösen.
Dr Hinner
06.12.2025
Sind das US-Billionen und Deutsche Milliarden bei den Parametern? Viele Deutsche kommen hier etwas durcheinander, deshalb wollte ich lieber nachfragen...
Klaus
13.09.2025
Besten Dank. Hat mit einem Mac Mini M4 16GB wunderbar funktioniert.
Phi4 hat mir schon nach 20 Minuten eine nette Geschichte erzählt.
Phi4 hat mir schon nach 20 Minuten eine nette Geschichte erzählt.
Diesen Artikel kommentieren:
Hinweis:
- Nur Fragen / Antworten direkt zum Artikel
- Kein Support für andere Hard- oder Software !

Spamfreies E-Mail Abo nur bei neuen Artikeln
